Last weekend, a motley crew of designers, students, developers, business and government people came together in Edinburgh to prototype designs and apps to help learners manage their journeys. With help, I built a prototype that showed how curriculum and course offering data can be combined with e-portfolios to help learners find their way.
The first official Scottish government data jam, facilitated by Snook and supported by TechCube, is part of a wider project to help people navigate the various education and employment options in life, particularly post 16. The jam was meant to provide a way to quickly prototype a wide range of ideas around the learner journey theme.
While many other teams at the jam built things like a prototype social network, or great visualisations to help guide learners through their options, we decided to use the data that was provided to help see what an infrastructure could look like that supported the apps the others were building.
In a nutshell, I wanted to see whether a mash-up of open data in open standard formats could help answer questions like:
- Where is the learner in their journey?
- Where can we suggest they go next?
- What can help them get there?
- Who can help or inspire them?
Here’s a slide deck that outlines the results. For those interested in the nuts and bolts read on to learn more about how we got there.
Where is the learner?
To show how you can map where someone is on their learning journey, I made up an e-portfolio. Following an excellent suggestion by Lizzy Brotherstone of the Scottish Government, I nicked a story about ‘Ryan’ from an Education Scotland website on learner journeys. I recorded his journey in a Mahara e-portfolio, because it outputs data in the standard LEAP2a format- I could have used PebblePad as well for the same reason.
I then transformed the LEAP2a XML into very rough but usable RDF using a basic stylesheet I made earlier. Why RDF? Because it makes it easy for me to mash up the portfolios with other datasets; other data formats would also work. The made-up curriculum identifiers were added manually to the RDF, but could easily have been taken from the LEAP2a XML with a bit more time.
Where can we suggest they go next?
I expected that the Curriculum for Excellence would provide the basic structure to guide Ryan from his school qualifications to a college course. Not so, or at least, not entirely. The Scottish Qualifications Framework gives a good idea of how courses relate in terms of levels (i.e. from basic to a PhD and everything in between), but there’s little to join subjects. After a day of head scratching, I decided to match courses to Ryan’s qualifications by level and comparing the text of titles. We ought to be able to do better than that!
The course data set was provided to us was a mixture of course descriptions from the Scottish Qualifications Authority, and actual running courses offered by Scottish colleges all in one CSV file. During the jam, Devon Walshe of TechCube made a very comprehensive data set of all courses that you should check out, but too late for me. I had a brief look at using XCRI feeds like the ones from Adam Smith college too, but went with the original CSV in the end. I tried using LOD Refine to convert the CSV to RDF, but it got stuck on editing the RDF harness for some reason. Fortunately, the main OpenRefine version of the same tool worked its usual magic, and four made-up SQA URIs later, we were in business.
This query takes the email of Ryan as a unique identifier, then finds his qualification subjects and level. That’s compared to all courses from the data jam course data set, and whittled down to those courses that match Ryan’s qualifications and are above the level he already has.
The result: too many hits, including ones that are in subjects that he’s unlikely to be interested in.
So let’s throw in his interests as well. Result: two courses that are ideal for Ryan’s skills, but are a little above his level. So we find out all the sensible courses that can take him to his goal.
What can help them get there?
One other quirk about the curriculum for excellence appears to be that there are subject taxonomies, but they differ per level. Intralect implemented a very nice one that can be used to tag resources up to level 3 (we think). So Intralect’s Janek exported the vocabulary in two CSV files, which I imported in my triple store. He then built a little web service in a few hours that takes the outcome of this query, and returns a list of all relevant resources in the Intralibrary digital repository for stuff that Ryan has already learned, but may want to revisit.
Who can help or inspire them?
It’s always easier to have someone along for the journey, or to ask someone who’s been before you. That’s why I made a second e-portfolio for Paula. Paula is a year older than Ryan, is from a different, but nearby school, and has done the same qualifications. She’s picked the same qualification as a goal that we suggested to Ryan, and has entered it as a goal on her e-portfolio. Ryan can get it touch with her over email.
This query takes the course suggested to Ryan, and matches it someone else’s stated academic goal, and reports on what she’s done, what school she’s from, and her contact details.
Conclusion
For those parts of the Curriculum for Excellence for which experiences and outcomes have been defined, it’d be very easy to be very precise about progression, future options, and what resources would be particularly helpful for a particular learner at a particular part of the journey. For the crucial post 16 years, this is not really possible in the same way right now, though it’s arguable that its all the more important to have solid guidance at that stage.
Some judicious information architecture would make a lot more possible without necessarily changing the syllabus across the board. Just a model that connects subject areas across the levels, and school and college tracks would make more robust learner journey guidance possible. Statements that clarify which course is an absolute pre-requisite for another, and which are suggested as likely or preferable would make it better still.
We have the beginnings of a map for learner journeys, but we’re not there yet.
Other than that, I think agreed identifiers and data formats for curriculum parts, electronic portfolios or transcripts and course offerings can enable a whole range of powerful apps of the type that others at the data jam built, and more. Thanks to standards, we can do that without having to rely on a single source of truth or a massive system that is a single point of failure.
Find out all about the other great hacks on the learner journey data jam website.
All the data and bits of code I used are available on github
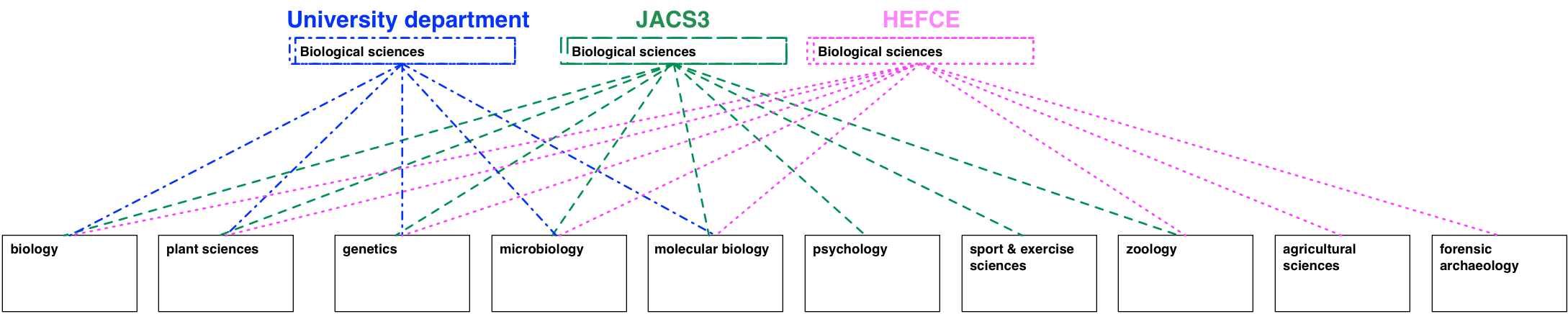 A consequence of the approach is that the familiar JACS3 codes (“L3xx” is anything sociological etc.) are no longer valid. From the perspective of HECoS “sociolinguistics” will therefore have no defined link with “sociology”, which is why the code for the former is “101016” –or a URI that encodes that number such as http://hecos.hediip.ac.uk/terms/101016– and the code for the latter is “100505”.
For ease of navigation, however, HECoS will come with some common groupings. There is a “sociology group” that has both “sociolinguistics” and “sociology” in it. This is just to help people find terms, and nodes like “sociology group” cannot be used to classify a degree programme or module.
Terms are based on demonstrated use, need and distinguishability
While JACS was reviewed periodically, it hasn’t always had formal acceptance criteria either for the terms that were already in there, or for newly proposed ones. HECoS does have a proposal for it, which has already been applied in the development of the current draft.
The criteria for the first cut were, in short:
A consequence of the approach is that the familiar JACS3 codes (“L3xx” is anything sociological etc.) are no longer valid. From the perspective of HECoS “sociolinguistics” will therefore have no defined link with “sociology”, which is why the code for the former is “101016” –or a URI that encodes that number such as http://hecos.hediip.ac.uk/terms/101016– and the code for the latter is “100505”.
For ease of navigation, however, HECoS will come with some common groupings. There is a “sociology group” that has both “sociolinguistics” and “sociology” in it. This is just to help people find terms, and nodes like “sociology group” cannot be used to classify a degree programme or module.
Terms are based on demonstrated use, need and distinguishability
While JACS was reviewed periodically, it hasn’t always had formal acceptance criteria either for the terms that were already in there, or for newly proposed ones. HECoS does have a proposal for it, which has already been applied in the development of the current draft.
The criteria for the first cut were, in short:
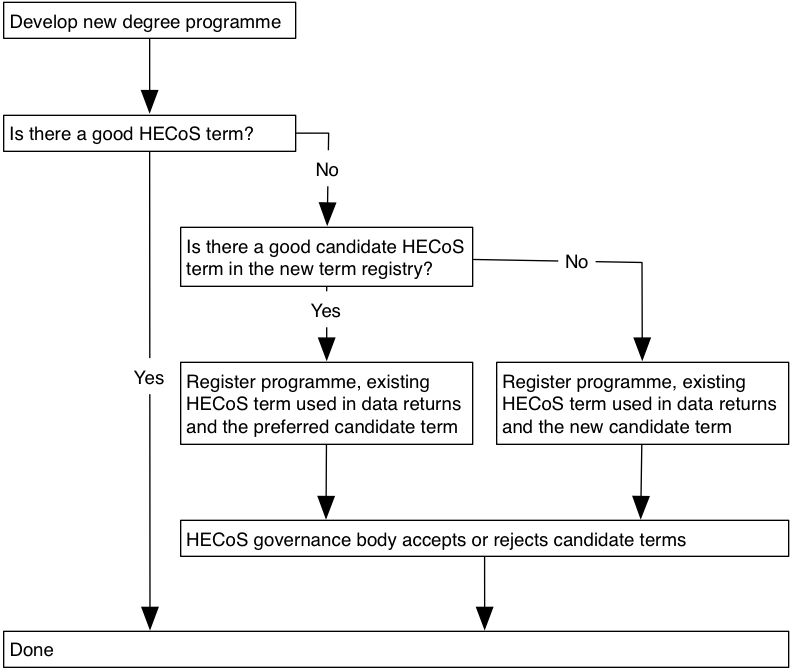 The proposed criteria for accepting a new term into HECoS proper are similar the ones used for the first draft: a term has to be demonstrably in use, or fill a need, and be distinguishable by non-specialists. In each case, though, the HECoS governance body, which is designed to represent the whole sector, will have the ultimate say on which terms will be accepted or retired, and how often these changes will happen.
The proposed criteria for accepting a new term into HECoS proper are similar the ones used for the first draft: a term has to be demonstrably in use, or fill a need, and be distinguishable by non-specialists. In each case, though, the HECoS governance body, which is designed to represent the whole sector, will have the ultimate say on which terms will be accepted or retired, and how often these changes will happen. 






