Cetis have published a new briefing paper on Activity Data and Paradata. The paper presents a concise overview of a range of approaches and specifications for recording and exchanging data generated by the interactions of users with resources.
Such data is a form of Activity Data, which can be defined as “the record of any user action that can be logged on a computer”. Meaning can be derived from Activity Data by querying it to reveal patterns and context, this is often referred to as Analytics. Activity Data can be shared as an Activity Stream, a list of recent activities performed by an individual. Activity Streams are often specific to a particular platform or application, e.g. facebook, however initiatives such as OpenSocial, ActivityStreams and Tin Can API have produced specifications and APIs to share Activity Data across platforms and applications.
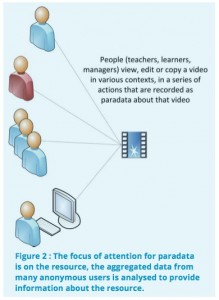 While Activity Streams record the actions of individual users and their interactions with multiple resources and services, other specifications have been developed to record the actions of multiple users on individual resources. This data about how and in what context resources are used is often referred to as Paradata. Paradata complements formal metadata by providing an additional layer of contextual information about how resources are being used. A specification for recording and exchanging paradata has been developed by the Learning Registry, an open source content-distribution network for storing and sharing information about learning resources.
While Activity Streams record the actions of individual users and their interactions with multiple resources and services, other specifications have been developed to record the actions of multiple users on individual resources. This data about how and in what context resources are used is often referred to as Paradata. Paradata complements formal metadata by providing an additional layer of contextual information about how resources are being used. A specification for recording and exchanging paradata has been developed by the Learning Registry, an open source content-distribution network for storing and sharing information about learning resources.
The briefing paper provides an overview of each of these approaches and specifications along with examples of implementations and links to further information.
The Cetis Activity Data and Paradata briefing paper written by Lorna M. Campbell and Phil Barker can be downloaded from the Cetis website here: http://publications.cetis.org.uk/2013/808
