Guest post
Dan Rehak talks about the Learning Registry, a new initiative offering an alternative approach to learning resource discovery, sharing and usage tracking. The Learning Registry prioritizes sharing and second party usage data and analytics over first party metadata. It’s an enabling infrastructure accessible by anyone, has no mandated data standards, can be replicated worldwide and is open, cloud-based, and app ready.
Isn’t this all too hard?
Let’s imagine that you’re a secondary school physics teacher and you want to build a lesson on orbital mechanics which combines elements of physics, maths, the history of the space program and a writing assignment. Where would you go to find the learning resources you need, either lessons to reuse or individual pieces? A search engine might help in finding the individual pieces, but even formulating a query for the entire lesson is difficult. If you want images and primary historic source material, you’ll probably have to search individual collections: NASA, the US National Archives, Smithsonian, Library of Congress, and probably multiple repositories for each. Let’s assume you found several animations on orbital mechanics. Can you tell which of these are right for your students (without having to preview each)? Is there any information about who else has used them and how effective they were? How can you provide your feedback about the resources you used, both to other teachers and to the organizations that published or curated them? Is there any way to aggregate this feedback to improve discoverability?
The Learning Registry.
The Learning Registry (http://www.learningregistry.org/) is defining and building an infrastructure to help answer these questions. It provides a means for anyone to “publish” information about their learning resources (both resources specifically created for education along with primary source materials, including historic and cultural heritage resources). It allows anyone to use the published information. Beyond metadata and descriptions, this information includes usage data, feedback, rankings, likes, etc.; we call this paradata. It provides a metadata timeline—a stream of activity data about a learning resource. It enables building better discovery tools (search, recommender systems), but it’s not a search engine, a repository, or a registry in the conventional sense.
Share. Find. Use. Amplify.
With the Learning Registry, anyone can put any information into the timeline, anyone can get it from the timeline, anyone can filter parts of it for their communities, and anyone can provide feedback, all through a distributed infrastructure. NASA could “announce” a new animation. The PBS (US Public Broadcasting Service) Teachers portal could be watching for NASA publishing events, and add the resource to their secondary school “Science and Tech” stream. The National Science Digital Library (NSDL) could also provide it via one of their “Pathways”. A teacher using the PBS portal could find it, rank it, comment on it, or share it via the PBS portal. PBS can publish this paradata back into the timeline. NSDL would see this new paradata and could update their information about the resource. NSDL paradata also flows back into the timeline. NASA could monitor the timeline and see how and where their resource is being used; the timeline and cumulative paradata provides more contextual information than just server access logs. This enables resource and information sharing, discovery, access, integration and knowledge amplification among producers, consumers and brokers. We believe that this paradata timeline can be more valuable than traditional metadata for learning resource discovery and that collaborative publishing to the network amplifies the available knowledge about what learning resources are effective in which learning contexts.
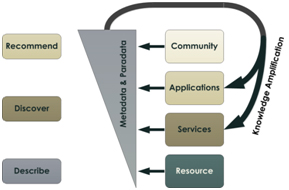
Share Find Use Amplify
The Infrastructure.
The operational Learning Registry is a light-weight learning resource information sharing network: a high-latency, loosely connected network of master-master synchronizing brokers (nodes) distributing resources, metadata and paradata. The network provides distributed publishing and access. There are simple RESTful+JSON core APIs (limited to publish, obtain, and distribute). You can publish anything to the timeline at any node and access it all from any other node. There is no central control, central registries or central repositories in the core resource distribution network. All data eventually flows to all nodes.
Apps and APIs.
We’re also defining a small set of non-core APIs for integration with existing edge services, e.g., SWORD for repository publishing, OAI-PMH for harvest from the network to local stores, SiteMaps for search engine exposure, ATOM for syndication, and we encourage people to build and share more APIs. We don’t provide (and don’t plan to provide) a search engine, community portal, recommender system, etc. We want the community to build their own value-added services on top of the core network infrastructure and are exploring a variety of tools and social plug-ins (e.g., Fedora, DSpace, Moodle, SAKAI, WordPress, Facebook). Thus while we’re defining the transport network, we only expect that it will be used directly by application developers. Teachers and students will interact with the timeline via their local environments, and shouldn’t know or care about the Learning Registry infrastructure. Our aim is only to provide the essential core features and to be enabling.
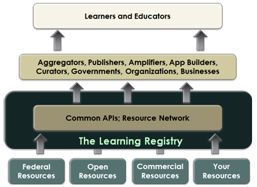
Apps and APIs
No Metadata Standards.
We don’t mandate any metadata or paradata formats nor do we attempt to harmonize—that would be futile. We encourage simple hashtags and allow “legacy” metadata in any format. We assume some smart people will do some interesting (and unanticipated) things with the timeline data stream (e.g., consider the JISC CETIS OER Technical MiniProject on the Analysis of Learning Resource Metadata Records as an example) and that sub-communities will gravitate towards shared approaches.
Cool Tech.
Our initial implementation is built upon CouchDB (a NoSQL document-oriented database with RESTful JSON APIs, native JavaScript code execution, MapReduce support, and distributed data replication). Our design approach is influenced by its capabilities and design, but the APIs provides an abstraction layer on top of Couch. We’re using Python as an application layer when needed, but apps can be built in your favorite environment. You can install and run a node on your own hardware (Linux, Windows or Mac) or you can stand up a node in the cloud; we’re currently hosting nodes on Amazon EC2. We’re aiming for zero-config installers to make adding a node to the network simple and fast.
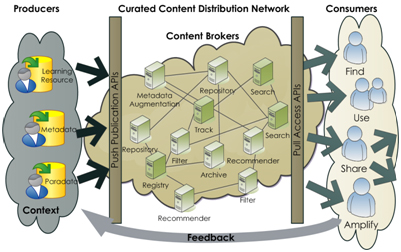
Learning Registry network infrastructure
The Project.
The project leadership comes from the U.S. Department of Education and U.S. Department of Defense, but we aim to be fully open and collaborative: open documents (CC-BY-3.0 in a public Google Docs collection: http://goo.gl/8I9Gc), open process (join our discussion list, participate in our calls [announced on the list], http://groups.google.com/group/learningregistry), open metadata and paradata (CC-BY-3.0), open source (Apache 2.0, code @ http://git.learningregistry.org/, project tracking @ http://tracker.learningregistry.org/), Open Spec (OWF, draft Spec @ http://goo.gl/2Cf3L). We’re working with a number of Governmental, NGO and commercial organizations worldwide. An initial public beta network is planned for September 2011; interested parties can connect to the testbed in April.
Try it @ OER Hackday.
We’re coming to Manchester. We have a working infrastructure with several operational nodes, basic installers, functioning core APIs and basic SWORD and OAI-PMH integration. We want to test our baseline and our other assumptions. We are interested in connecting to various sources (testing our APIs) and building sufficient data to try “interesting things”. We want to understand what value-added APIs are useful, explore doing things with the paradata timeline and mashup the Learning Registry with other tools (e.g., we’re exploring IndexTank as an external search index). Our rule of thumb is that it should take at most two hours to understand an API and less than a day to build something useful with it. Are we on track?
About Dan
Daniel R. Rehak, Ph.D., is Senior Technical Advisor, Advanced Distributed Learning Initiative (ADL) where he provides technical expertise in the areas of systems design, information management and architecture, with emphasis on learning and training technologies. He provides technical leadership to the DoD for the development of the Learning Registry.