Over the summer I’ve done a couple of presentations about what schema.org is and how it is implemented (there are links below). Quick reminder: schema.org is a set of microdata terms (itemtypes and properties) that big search engines have agreed to support. I haven’t said much about why I think it is important, with the corollary of “what it is for?”.
The schema.org FAQ answers that second question with:
…to improve the web by creating a structured data markup schema supported by major search engines. On-page markup helps search engines understand the information on web pages and provide richer search results. … Search engines want to make it easier for people to find relevant information on the web.
So, the use case for schema.org is firmly anchored around humans searching the web for information. That’s important to keep in mind because when you get into the nitty gritty of what schema.org does, i.e. identifying things and describing their characteristics and relationships to other things, in the context of the web, then you are bound to run into people who talk about the semantic web, especially because the RDFa semantic web initiative covers much of the same ground as schema.org. To help understand where schema.org fits into the semantic web more generally it is useful to think about what various semantic web initiatives cover that schema doesn’t. Starting with what is closest to schema.org, this includes: resource description for purposes other than discovery; descriptions not on web pages; data feeds for machine to machine communication; interoperability for raw data in different formats (e.g. semantic bioinformatics); ontologies in general, beyond the set of terms agreed by schema.org partners, and their representation. RDFa brings some of this sematic web thinking to the markup of web pages, hence the overlap with schema.org. Thankfully, there is now an increasing overlap between the semantic web community and the schema.org community, so there is an evolving understanding of how they fit with each other. Firstly, the schema.org data model is such that:
“[The] use of Microdata maps easily into RDFa Lite. In fact, all of Schema.org can be used with the RDFa Lite syntax as is.”
Secondly there is a growing understanding of the complementary nature of schema.org and RDFa, described by Dan Brickley; in summary:
This new standard [RDFa1.1], in particular the RDFa Lite specification, brings together the simplicity of Microdata with improved support for using multiple schemas together… Our approach is “Microdata and more”.
So, if you want to go beyond what is in the schema.org vocabulary then RDFa is a good approach, if you’re already committed to RDFa then hopefully you can use it in a way that Google and other search engines will support (if that is important to you). However schema.org was the search engine providers’ first choice when it came to resource discovery, at least first in the chronological sense. Whether it will remain their first preference is moot but in that same blog post mentioned above they make a commitment to it that (to me at least) reads as a stronger commitment than what they say about RDFa:
We want to say clearly that we continue to support Microdata
It is interesting also to note that schema.org is the search engine company’s own creation. It’s not that there is a shortage of other options for embedding metadata into web pages, HTML has always had meta tags for description, keywords, author, title; yet not only are these not much supported but the keywords tag especially can be considered harmful. Likewise, Dublin Core is at best ignored (see Invisible institutional repositories for an account of the effect of the use of Dublin Core in Google Scholar–but note that Google Scholar differs in its use of metadata from Google’s main search index.)
So why create schema.org? The Google schema.org faq says this:
Having a single vocabulary and markup syntax that is supported by the major search engines means that webmasters don’t have to make tradeoffs based on which markup type is supported by which search engine. schema.org supports a wide collection of item types, although not all of these are yet used to create rich snippets. With schema.org, webmasters have a single place to go to learn about markup for a wide selection of item types, search engines get structured information that helps improve search result quality, and users end up with better search results and a better experience on the web.
(NB: this predates the statement quoted above about “Microdata and more” approach)
There are two other reasons I think are important: control and trust. While anyone can suggest extensions to and comment on the schema.org vocabulary through the W3C web schemas task force, the schema.org partners, i.e. Google, Microsoft Bing, Yahoo and Yandex pretty much have the final say on what gets into the spec. So the search engines have a level of control over what is in the schema.org vocabulary. In the case of microdata they have chosen to support only a subset of the full spec, and so have some control over the syntax used. (Aside: there’s an interesting parallel between schema.org and HTML5 in the way both were developed outwith the W3C by companies who had an interest in developing something that worked for them, and were then brought back to the W3C for community engagement and validation.)
Then there is trust, that icing on the old semantic web layer cake (perhaps the cake is upside down, the web needs to be based on trust?). Google, for example, will only accept metadata from a limited number of trusted providers and then often only for limited use, for example publisher metadata for use in Google Scholar. For the world in general Google won’t display content that is not visible to the user. The strength of the microdata and RDFa approach is that what is marked up for machine consumption can also be visible to the human reader; indeed if it the marked-up content is hidden Google will likely ignore it.
So, is it used? By the big search engines, I mean. Information gleaned from schema.org markup is available in the XML can be retrieved using a Google Custom Search Engine, which allows people to create their own search engines for niche applications, for example jobs for US military veterans. However, it is use on the main search site, which we know is the first stop for people wanting to find information, that would bring about significant benefits in terms the ease and sophistication with which people can search. Well, Google and co. aren’t known for telling the world exactly how they do what they do, but we can point to a couple of developments to which schema.org markup surely contributes.
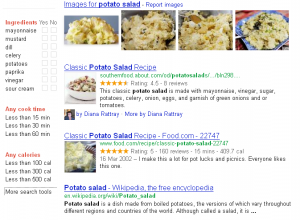
First, of course, is the embellishment of search engine result pages that the “rich snippets” approach allows: inclusion of information such as author or creator, ratings, price etc., and filtering of results based on these properties. (Rich snippets is Google’s name for the result of marking up HTML with microdata, RDFa etc., which predates and has evolved into the schema.org initiative).
Secondly, there is the Knowledge graph, which while it is known to use FreeBase, and seems to get much of its data from dbpedia, has a “things not strings” approach which resonates very well with the schema.org ontology. So perhaps it is here that we will see the semantic web approach and schema.org begin to bring benefits to the majority of web users.
See also
{kind=link}