The other week I applied for some project funding from JISC under the rapid innovation call. The idea behind the call is to promote “small” and/or “risky” and/or “mad” projects which can be done in a short timescale and do innovative things. The terms being that projects have to fulfil some specific community need in higher education.
I don’t yet know if the bid is going to be successful but obviously I’ve got my fingers crossed, meanwhile I feel it’s worth getting some of my plans and ideas out there for comment.
The project is called Artnotes, the inspiration for it coming from visiting an artist friend of mine who showed me her notebook. It was full of doodles, scribblings, postcards and photographs of artwork she had seen, taped-up pages of things she didn’t want to destroy so much as save for another time. It was a beautiful and very tactile thing full of memories and influences.
It got me thinking, could you do something like that digitally? Could you use mobile devices (such as the iPhone – which I’ve been getting into coding for on my own back) to let artists and others catalogue and document their visual noodlings and found objects in a way that didn’t loose too much of the lovelyness of a real book but enabled all sorts of modern webby things – like being able to search through public image repositories and museum catalogues for images, like being able to share the book back out to the world. So I did a bit of reading around the subject, worried greatly about rights issues and risks, talked to a few other people round the community, panicked at the last minute and got a bid together.
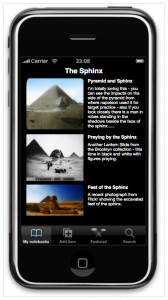
If you’re interested, take a look at the BID DOCUMENT (reproduced here sans coversheets and budget) which explains the scope of the project and includes a bunch more mockups and planned features.
The trouble with ideas is that they tend to spawn more ideas – much of the work that went into the bid was in trying to cut it down and keep it limited to the core of what I thought the tool needed to be effective. Hopefully I’ve done this in the bid while not being too conservative.
One of the “cool” ideas that didn’t make it and is probably a separate project in its own right was to provide some kind of image recognition service hooking into the catalogues of major galleries. Along the lines of being able to walk into a gallery, snap a picture of an exhibit and be delivered a link to the entry in the museum’s (publicly available and machine readable obviously) catalogue. I’ve been following the work of the Museum API efforts set up by Mike Ellis and contributed to by many others which seems to be making some inroads into getting the necessary underpinnings of this in place. Of particular interest are technologies such as hoard.it which already does data aggregation across a number of museums, the exemplary Brooklyn Museum API which lets you dig deep into their collection, and on the image recognition side Tineye which does a very similar reverse-image-search on the web at large.
The service which for the sake of convenience I’ve dubbed GIRDS (Gallery Image Recognition and Discovery Service) at first cut be a web-api (and probably a very lightweight browser-based interface) and would work a little like this:

girds diagram
Better names for it are obviously most welcome!
If anything the GIRDS service would fit more in the category of mad than Artnotes and perhaps would have been a better one to submit for the call. However to my mind getting the nice user interface through the iPhone done first and then adding the image recognition capabilities through GIRDS later seems the right way to go about it. Unless of course anyone else fancies pitching in with either project (they are both going to have to be open source after all).
Irrespective of whether my bid for Artnotes is successful I’m feeling very strongly that this work is taking me back to my roots – dreaming up nice workable tools which can potentially be of some benefit to learners, teachers, researchers or the wider community.