I’ve been attending a course on The Open Group Architecture Framework or TOGAF down in London. The aim of TOGAF is to provide a methodology for effecting change in the IT capabilities of an organisation by taking a consistent (though perhaps rather top-down) approach to structuring everything through analysing the business needs and processes…
The course run by Architecting the Enterprise was pretty power-point-heavy and by the end of the first day we were all getting pretty sleepy. There was plenty of terrible clip art and bullets bullets bullets. The second day was slightly better as we were all that little bit more awake but still there was a general consensus that the balance could be more on the workshopping of the case-study as a means to teach the method rather than the endless transmission. They are doing the job of giving us an understanding of the methodology – my criticism is simply a question of style.
The first principle of TOGAF is to put in place an architecture process – or Architecture development model – mapping out the business needs, applications, data and infrastructure which go to make things work. Simply thinking about the architecture you’re planning to put in place, who the stakeholders are, scoping it out sensibly, getting the right solutions and planning the migrations in a structured, iterative manner, considering risks etc etc should clearly help organisations to run a more efficient and tight ship in terms of alignment of IT with the actual business needs. The daisy below shows the model, each petal representing a core element of the process, all feeding the central requirements. In this diagram one petal is expanded to show the sub-process within….
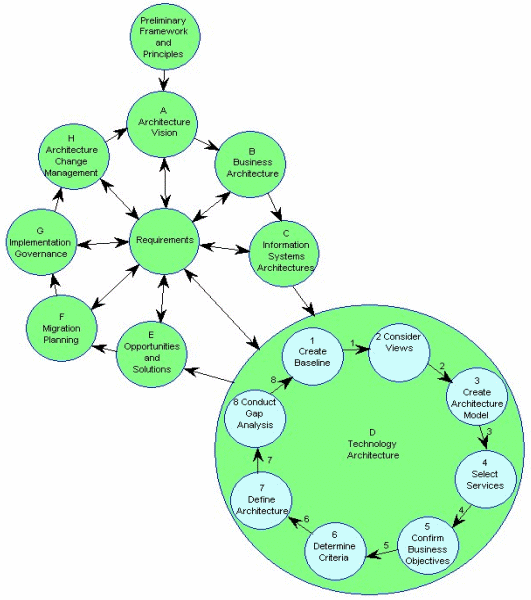
Togaf’s Architechture Development Model (as exploded by developer.com)
The question for us in Education is of course how does this gel with the constraints in which we work – how we get the buy in from both the top and bottom of the organisation to such an approach. Can it be applied in a more light-weight way, how do we deal with the technological shanty-towns that exist in academia. Ultimately we figured out that going through the initial stages of the methodology would probably serve to expose a lot of cultural issues and barriers to change within the organisation.
By way of context, the other participants of the course are mostly working on JISC Enterprise Architecture projects and actually have responsibility for applying these things in their own organisations.
There are a range of certified modelling tools for TOGAF – but it should be noted that there are other “un-certified” tools which could concievably be used to model and manage the togaf process. As ever with these kind of things they will all havetheir specific uses, affordances, personal fans, strengths, weaknesses and so forth. We were not given a specific push towards one tool within the training course but we were given some criteria by which to evaluate them; Core questions – does it support the ADM process, deliverables, models and how the tool handles import/export and extensibility. Most significantly though is probably usability and cost of ownership – which varies wildly across the available products from circa $100 per seat to thousands and thousands.
To be continued…