During last week’s EDUPUB workshop, I presented a demo of how an IMS QTI 2.1 question item could be embedded in an EPUB3 e-book in a way that is engaging, but also works across many e-book readers. Here’s the why and how.
One of the most immediately obvious differences between a regular book and an e-textbook is the inclusion of little quizzes at the end of a chapter that allow the learner to check their understanding of what they’ve just learned. Formative assessment matters in textbooks.
When moving to electronic textbooks, there is a great opportunity to make that assessment more interactive, and provide richer feedback, and connect the learning to a wider view of how a student is doing (i.e. learning analytics). The question is how to do that in a way that works across many e-reading devices and applications, on a scale that works for publishers.

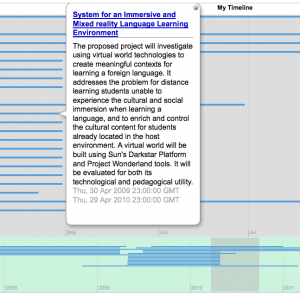
QTI item in Adobe Editions
Scalability is where interoperability standards like EPUB3, IMS Learning Tool Interoperability (LTI) and IMS Question and Test Interoperability (QTI) 2.1 come in. People use a large number of different software systems in the authoring, management, and playback of e-books. Connecting each of those to all the others with one-off custom integrations just gets too complex, too expensive and too brittle; that’s why an increasing number of publishers and software vendors agreed on the EPUB specification. As long as you implement that spec, solutions can scale across many e-book applications. The same goes for question and test material, where IMS QTI does the same job. LTI does that job for connecting VLEs to any online learning tool.
Which leaves the question of how to square the circle of making the assessment experience as engaging and effective as possible, but also work on devices with very different capabilities.
Fortunately, EPUB3 files can include a number of techniques that allow an author to adapt the content to the capability of the device it is being read on. I used those techniques to present the same QTI item in three different ways; as a static quiz – much like a printed book –, as a simple interactive widget and as a feedback rich test run by an online assessment system inside the book. The latter option makes detailed analytics data available and it should also make it possible to send a grade to a VLE automatically.
The how
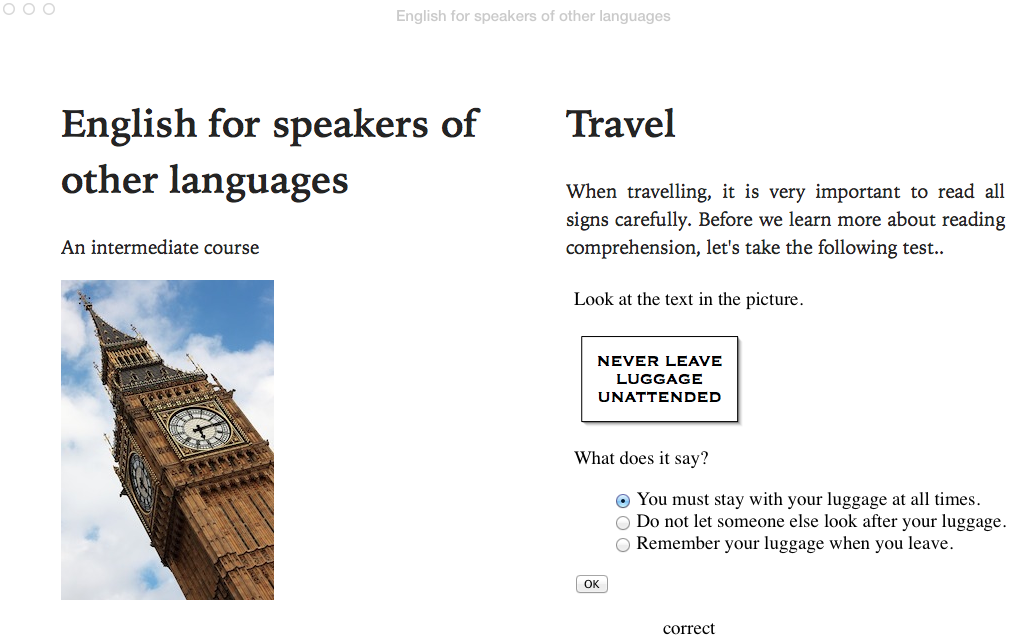
QTI item in Apple iBooks
For the static representation and the interactive widget, I relied on Steve Lay’s rather brilliant transform from QTI XML to HTML5 (and back again), and to make the HTLM5 interactive with some javascript. By including this QTI HTML5 in the EPUB, you get all the advantages of standard QTI, in a way that still works in a simple, offline reader such as Adobe Editions as well as more capable software such as Apple’s iBooks.
For the most capable, online ebook readers such as Readium, the demo e-textbook connects to QTIWorks, an online QTI compliant assessment engine. It does that via IMS LTI 1.1, but in a somewhat unusual way: in LTI terms, the e-book behaves as a tool consumer. That is; like a VLE. Using a hash of an Oauth secret and key, it establishes a connection to QTIWorks, identifies the user, and retrieves the right quiz to show inside the ebook. A place to send the results of the quiz to is also provided, but I’ve not tested that yet. QTIWorks makes detailed report available of what the learner did exactly with each item, which can be retrieved in a variety of machine readable formats.
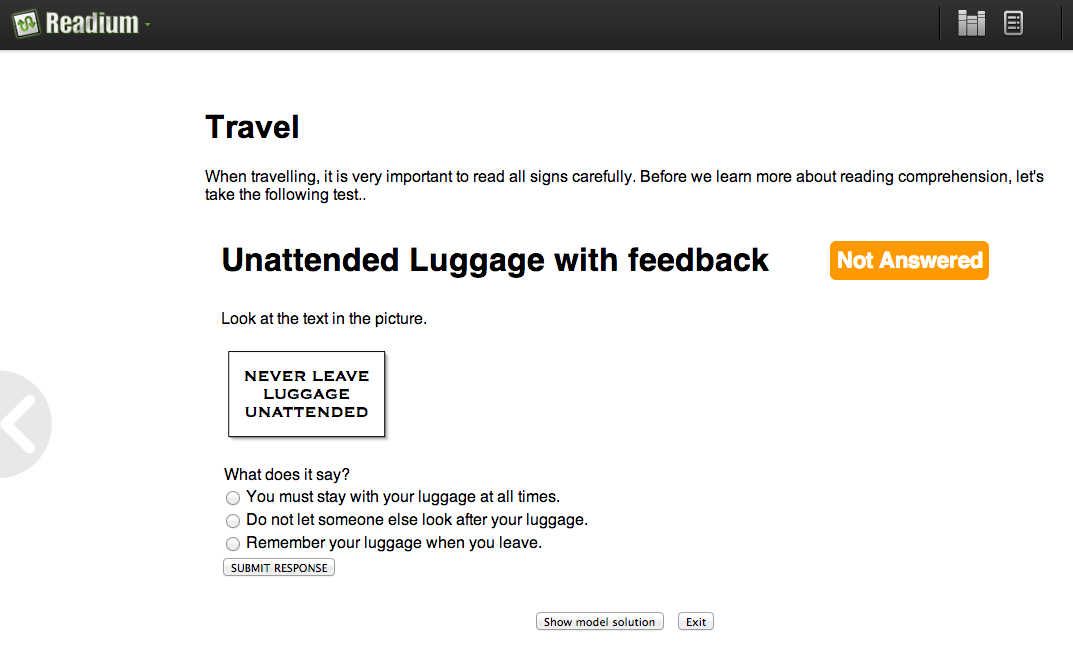
QTI item in Readium
Because the secret and the key have to be included in the book, the LTI connection the book establishes is not as secure as an LTI connection from a proper VLE. For access to some formative assessment, that may be a price worth paying, though.
The demo EPUB3 uses both scripting and some metadata to determine which version of the QTI item to show. The QTI item, the LTI launch and the EPUB textbook are all valid according to their specifications, and rely on stock readers to work.
Acknowledgements and links
David McKain for making QTIWorks
Steve Lay for the QTI HTML transforms
John Kristian of the OAuth project for the OAuth javascript library
Stephen Vickers for the ceLTIc IMS LTI development tools
The (ugly, content-less) demonstration EPUB3 and associated code is available from Github.