I posted a while ago about my upcoming move to the USA and today is my last working day at CETIS. Later in the week I’ll be getting on a plane to head over to Seattle and continue job-hunting on the West Coast. I’m looking forward to the challenge and new opportunities but will miss my colleagues and all those I’ve worked with (in particular all those who have been involved in UKOER). I’ve really enjoyed working with the programmes and thinking through the differences, pitfalls, and opportunities openness affords. I’ll look forward to hearing in due course how the Phase 3 and Rapid Innovation projects develop. I am very grateful for the opportunity I’ve had to work for CETIS and have been privileged to work with some great people.
No matter how carefully planned a move may be there are always unfinished fragments – the paper you’ll need to shelve for a while, the draft blog posts which either never quite got finished or never got beyond the record of a neat idea. As a way of rounding of my time with CETIS I wanted to mention some of the more recent blog posts which never quite made it (with apologies if this is more waffle than normal). [Rowin's blogged about all of our most popular and favourite published posts of 2011].
Identity, Emigration, and Learning
this post tried to draw together some of the thoughts and conversations I’ve had in the past year about culture, identity, and the opportunity for reflection and learning that they have presented. My reflections are still in process but I’m grateful for how twitter, conferences, and ds106radio have triggered opportunities and conversations which have helped me think through what we’re doing. In particular I’d have to single out @easegill for conversations about change, kids, and songs of emigration.
Kickstarter, innovation, and project bids
A post on my experiences with Kickstarter and experience as a backer. This post stalled because it became more about boardgames than about funding (and as much as I love games it is not what I’m paid to write about). The part which was of wider interest was thinking about good pitches vs good delivery and the importance of post-funding communication. It is a bit different for projects in JISC world but as Lorna and Amber are fond of saying – “as a project you can’t fail if you’re open about the process” It also might have talked about the increasing ‘subversion’ or ‘success’ of Kickstarter as it is increasing used by commercial companies (in boardgames at least) to fund their first print run and remove some of their risks – prompting a reflection on a) to what extent institutions are actually capitalising on JISC funding to fund institutional change, and b) how hard it is to make the funding process lightweight and attract interest from those who don’t regularly bid.
Next Generation Interfaces
This was another post inspired somewhat by games, but more about the radical shifts that we’re experiencing in consumer technology and the impact they will have on innovation. In themselves cameras and motion sensing are nothing new, but the availability of technology like the kinect in a relatively inexpensive consumer format (and upcoming mainstream release for windows) is likely to create affordances for all sorts of possibilities for innovation. Yes, it’s gimicky and fiddly but I also think it’s going to be one of those quiet leaps forward that changes how computers integrate into life and education .
copyright, zero cost reproduction, non-rivalrous goods
Prompted by a debate over a university sticking a copyright license on a digitized copy of a work which was in the public domain. I agreed and disagreed with this post all over the place – the intellectual content of it is in the public domain but the recreation and availability of a given version is a different discussion – I want to say the digitized copy should be free and pd but I know first hand what it costs to make such things, the relative lack of support for doing so, and the genuine creative work that can go into it (and how tightly institutions hold IPR of their offline special collections [which is incidentally why this whole discussion was a bit odd]). I could make tangential points for and against this and wish it could be open but in the wider discussion (not the original post) I found the lack of appreciation of the work and costs involved to be an unhelpful simplification.
opened11
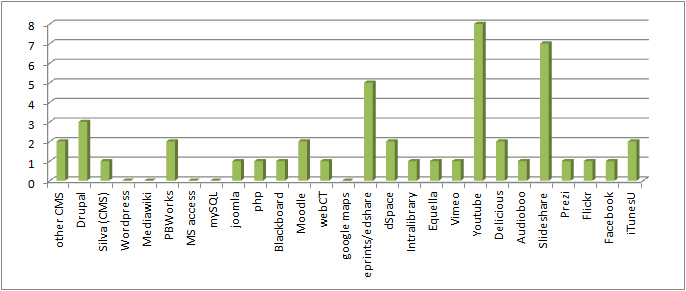
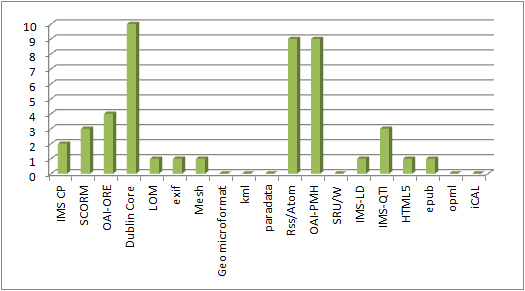
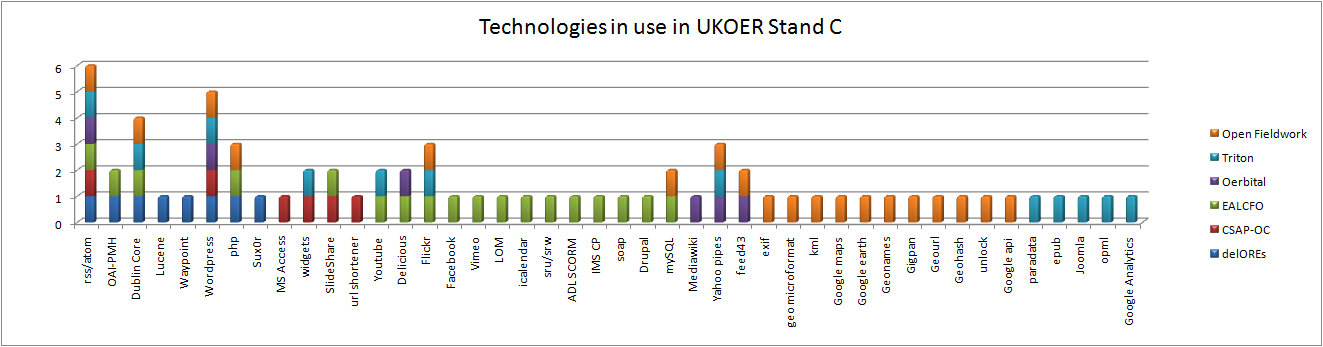
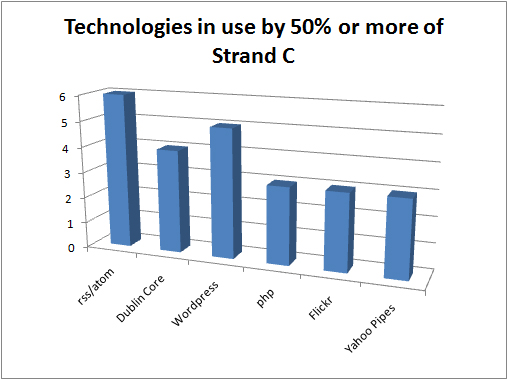
given how much I’ve written about oer and ukoer lots could be said about the number of my unfinished posts relating to open but frequently for these unfinished posts it was simply that at times someone else said it first, said it well, and it was better to point out their work than to finish a post saying the same thing.
Looking forward
This blog will continue to exist here but I’ve also copied it onto kavubob.wordpress.com and hope to continue it there.