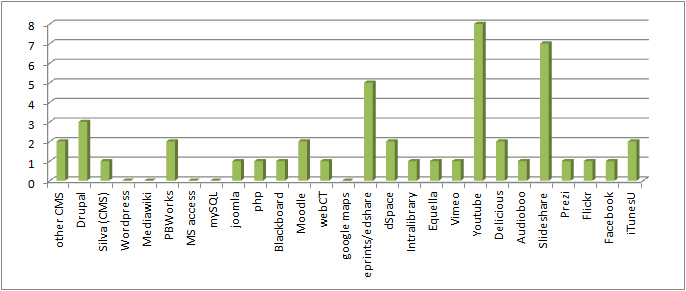
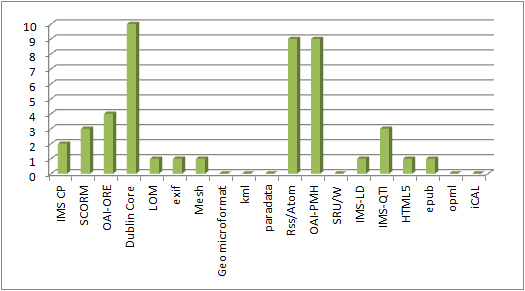
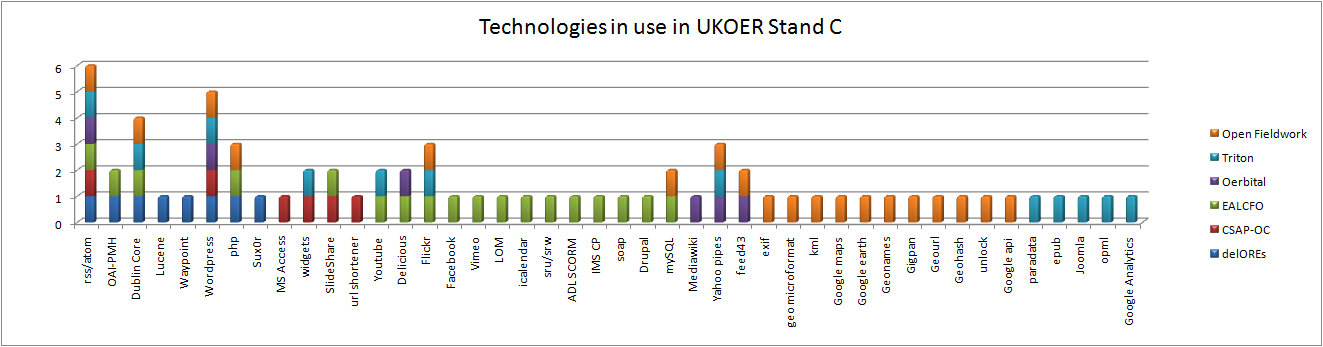
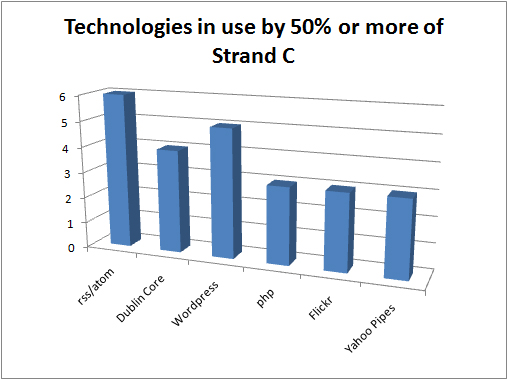
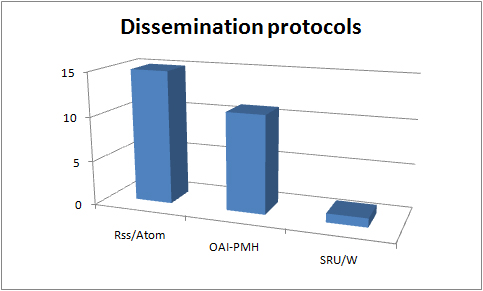
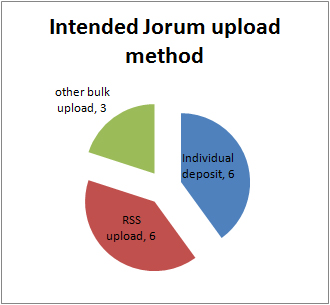
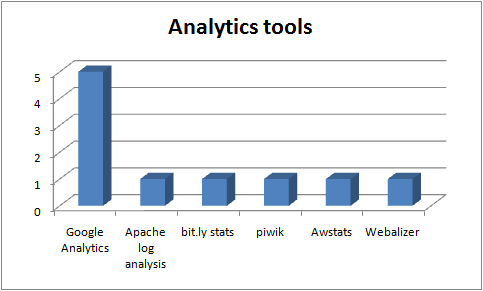
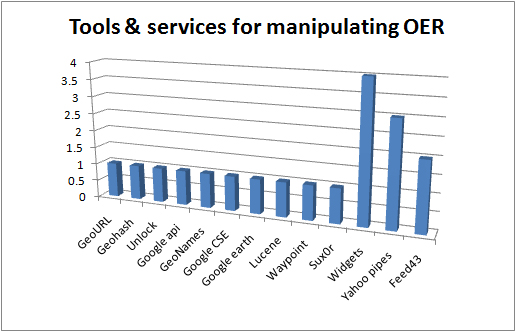
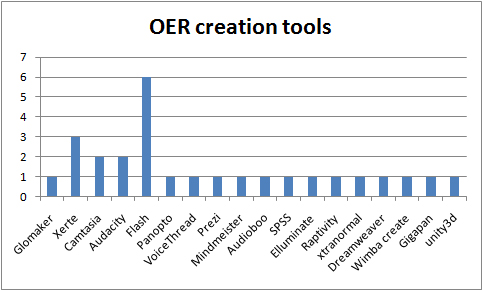
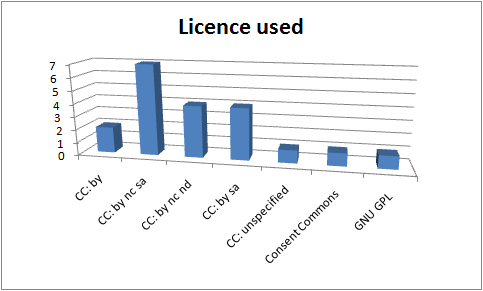
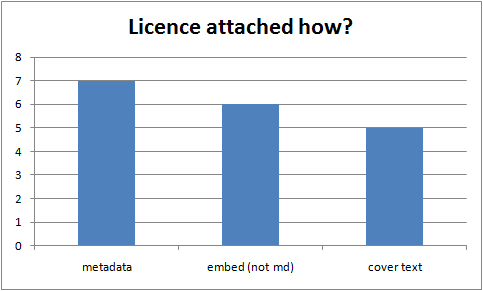
“The responsibility of acquiring books was the libraries and you might therefore think of extending the libraries role to…educational resources in general” p 21 (Nikoi, S. (2010) “Open Transferable Technology enabled Educational Resources (OTTER) project: Stakeholder Views on Open Educational Resources” Research Report, University of Leicester)
About a month ago I tweeted that we CETIS and CAPLE had a visiting scholar working with us for this semester. I’d like to take this opportunity to more comprehensively introduce Gema, some of the work she’s doing while she’s with us, and plug our survey investigate the role of academic libraries in OER efforts (you’ll remember I ran a study in this area last year).
Gema Bueno de la Fuente is a visiting scholar from the Library and Information Science Department, University Carlos III of Madrid, Spain where she works as an assistant professor teaching in several Undergraduate and Graduate Programs, e.g. the Master in e-Learning Production and Management. She holds a PhD. in Library Science since 2010 with the dissertation “An Institutional Repository of Educational Content (IREC) Model: management of digital teaching and learning resources in the university library”. Her main research interests are digital teaching and learning materials, open content, digital repositories and e-learning systems, with and special focus on the library role in these topics, mainly related to metadata, vocabularies and some specific standards.
While she’s at Strathclyde she’s working on two projects, one looking at OERs and Libraries and one looking at institutional practice in managing learning materials. She’s primarily working with myself and Stuart Boon (one of the lecturers in CAPLE). The survey Gema has created and introductory email are copied below:
“The Centre for Academic Practice & Learning Enhancement (CAPLE) and Centre for Educational Technology and Interoperability Standards (CETIS) at the University of Strathclyde are conducting a study about the involvement of the Library as an organizational unit, and of individual librarians and other information science specialists, in OER initiatives. OER (Open Educational Resources) are “digitised materials offered freely and openly for educators, students and self-learners to use and reuse for teaching, learning and research” (OECD, 2007).
This survey (http://www.surveygizmo.com/s3/669964/OER-Libraries-and-librarians) is open to any institution or initiative dealing with OER and/or open content for learning and teaching in a Higher Education context. This includes the creation and release of OER, its dissemination and promotion, the implementation of learning repositories or others management and publishing systems, the aggregation of open educational content, etc. Those projects focused solely on open educational practice are out the intended scope of this survey.
The survey should be answered by an individual OER initiative team member with an overview of current activity and the team composition and profiles. The survey instrument has 15 questions and the estimated time for completion is 15-20 minutes.
No personal data will be required, but you will be able to provide some basic information about your type of organization and OER initiative purpose and objectives if you wish. Participating organisations will be listed in the study report but responses are not connected to individual participants.
The results will be published in a report through JISC CETIS Open Educational Resources web page. If you want to receive a free PDF copy of the final report, please provide your email address at the end of the survey (your email will not be published or held beyond distribution of the survey results).
The survey is open for your feedback until Friday, November 4, 2011.
Thank you in advance for participating in this study, your contribution is very valuable to us.
BEGIN THE STUDY BY GOING TO THIS LINK: http://www.surveygizmo.com/s3/669964/OER-Libraries-and-librarians
Please feel free to forward this survey to any interesting parties or lists.
For further information, please contact:
Gema Bueno de la Fuente (Visiting Scholar from University Carlos III, Spain) (gema.bueno@strath.ac.uk), R. John Robertson (robert.robertson@strath.ac.uk) and Stuart Boon (stuart.boon@strath.ac.uk).
Centre for Educational Technology and Interoperability Standards (CETIS) / Centre for Academic Practice & Learning Enhancement (CAPLE). University of Strathclyde, Glasgow (UK).”