March sees the end of the JISC funded XCRI Support Project as it signs off leaving the development of the XCRI (eXchanging Course Related Information) specification for sharing (and advertising) course information looking very healthy indeed.
The support project picked up where the original XCRI Reference Model project left off. Having identified the marketing and syndication of course descriptions as a significant opportunity for innovation – due to the general practice in this area being one of huge efforts around re-typing of information to accommodate various different systems, sites and services…then to have that information maintained separately in various places – the XCRI Reference Model project mapped out the spaces of course management, curriculum development and course marketing and provided the community with a common standard for exchanging course related information. This would streamline approaches to the syndication of such information and give us the benefits of cost savings when it comes to collecting and managing the data and opens up the opportunities for a more sustainable approach to lifelong learning services that rely on course information from learning providers.
Over the course of the next three years the XCRI Support project developed the XCRI Course Advertising Profile (XCRI-CAP), an XML specification designed to enable course offerings to be shared by providers (rather like an RSS feed) and by other services such as lifelong learning sites, course search sites and other services that support learners in trying to find the right courses for them. Through the supervision and support of several institutional implementation projects the support project – a partnership between JISC CETIS at the University of Bolton (http://bit.ly/PZdKw), Mark Stubbs of Manchester Metropolitan University (http://bit.ly/PZdKw) and Alan Paull of APS Limited (http://bit.ly/cF6Fhd) – promoted the uptake and sustainability of XCRI through engagement with the European standards process and endorsement by the UK Information Standards Board. Through this work the value of XCRI-CAP was demonstrated so successfully as to ensure it was placed on the strategic agenda of national agencies.
Hotcourses manages the National Learning Directory under contract from the Learning and Skills Council (LSC). With over 900,000 course records and 10,000 learning providers the NLD is possibly the largest source of information about learning opportunities in the UK, which learners and advisers can access through dozens of national, regional and local web portals. Working with a number of Further Education colleges Hotcourses is now developing and piloting ‘bulk upload’ facilities using XCRI to ease the burden on learning providers supplying and maintaining their information on the NLD. UCAS also continues to make progress towards XCRI adoption. Most recently, at the ISB Portfolio Learning Opportunities and Transcripts Special Interest Group on January 27, 2010, UCAS colleagues described a major data consolidation project that should pave the way for a data transfer initiative using XCRI, and cited growing demand from UK HEIs for data transfer rather than course-by-course data entry through UCAS web-link. The project is a two-phase one, with XCRI implementation in phase II, which is due to deliver sometime in 2011.
Having ensured that the specification gained traction and uptake the project has worked extensively at developing the core information used by XCRI into a European Norm with harmonisation from other standards that addressed this space developed elsewhere across Europe. It is this process which has seen the evolution of XCRI from a standalone specification to a UK application profile of a recognised international standard. This could now be transitioned to an actual British Standard through BSI IST 43 (the committee of the British Standards Institution which looks at technical standards for learning education and training). At the same time adoption of the specifications were continued to be supported through engagement with policymakers and suppliers while the technical tools developed for adopters continued to be updated and maintained.
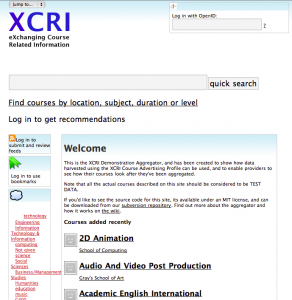 A couple of key tools were developed by the support project to assist implementers of XCRI. An aggregator engine was setup and maintained by the project and is demonstrated at http://www.xcri.org/aggregator/. This shows how its possible to deploy an aggregator setup that pulls in courses from several providers, and offers a user interface with basic features such as searching, browsing, bookmarking, tags and so on. It also demonstrates some value-added aspects such as geocoding the course venues and displaying them on Google Maps. Once you’ve had a look at the demonstrator you can get hold of the code for it at http://bit.ly/9eViM2
A couple of key tools were developed by the support project to assist implementers of XCRI. An aggregator engine was setup and maintained by the project and is demonstrated at http://www.xcri.org/aggregator/. This shows how its possible to deploy an aggregator setup that pulls in courses from several providers, and offers a user interface with basic features such as searching, browsing, bookmarking, tags and so on. It also demonstrates some value-added aspects such as geocoding the course venues and displaying them on Google Maps. Once you’ve had a look at the demonstrator you can get hold of the code for it at http://bit.ly/9eViM2
The project also developed an XCRI Validator to help implementers check their data structure and content. This goes beyond structural validation to also analyse content and provide advice on common issues such as missing information. Currently the development of this is very much at a beta stage but implementers can try out this early proof-of-concept at http://bit.ly/aeLArY. Accompanying this is a blog post describing how to use the validator at http://bit.ly/aHoJtH
Up to press there have been around 15-20 “mini-projects” which were funded to pilot implementation of XCRI within institutions. These looked at developing course databases using the specification, extending existing systems and methods to map to XCRI and the general implementation of generating the information and the exporting of this via web services. Not to say that this was the only project activity around XCRI. Various other Lifelong Learning projects have had an XCRI element to them along the way and all these have contributed to forming an active community around the development and promotion of the spec.
This community’s online activity is centred around a wiki and discussion forum on the XCRI Support Project website at http://xcri.org and while the support project is now officially at an end, the website will stay around as long as there is a community using it – currently its maintained by CETIS. Some XCRI.org content may move to JISC Advance as XCRI moves from innovation into mainstream adoption. However, as long as people are trying out new things with XCRI – whether thats vocabularies and extensions or new exchange protocols – then XCRI.org provides a place to talk about it, with the LLL & WFD project at Liverpool (CCLiP – http://www.liv.ac.uk/cll/cclip/) currently looking at how to improve the site and provide more information for non-technical audiences.
More information on the XCRI projects can be found at the JISC website, specifically at http://bit.ly/awevwQ