As my colleague Scott wrote recently, the European Standards body CEN has endorsed a “Workshop Agreement” on Metadata for Learning Opportunities (MLO) [final draft of MLO CWA], and made a commitment to develop a European standard (an EN) based on it. Continue reading
LMAP Scoping Study draft report
Some time back I started a scoping study into a potential Learning Materials Application Profile (LMAP) for the JISC. Well, I have at last written a draft report that is fit to be read by others, for comment.
It is rather long, and I don’t expect that anyone will want to do any more than look at the section that is relevant to your own interests. But if anyone is interested in taking a sneak preview then do please have a look and let me know of anything you spot that is wrong or misleading. (In my opinion it gets better as it goes along.)
I have some more work to do on it, filling in references, adding acknowledgments etc, that will take me a couple of weeks at least. Any comments received before I get those finished will be considered in the final report submitted to JISC.
Update, 11 Dec 2008: Thank you for your comments. The report as submitted to JISC is now available. I’m hoping they don’t want too many changes made.
FRBRizing learning materials
I may have bitten off more than I can chew. I wanted an example for showing how the Functional Requirements for Bibliographic Records (FRBR) might be applied to a typical learning resource. I’m not entirely sure that there is such a thing as a typical learning resource, but the OpenYale online lectures seemed seemed like reasonable candidates. I chose one on Newton’s Laws of Motion as my example because it’s a subject I like. I’m no expert on FRBR. If I was I would probably have known better than to choose a complex aggregation of different media types as my example (but would that have been typical?). Anyway, with some help from John Robertson, I came up with the diagram below. (It doesn’t quite model the example: I’ve modelled overhead display content in PowerPoint rather than in chalk.)
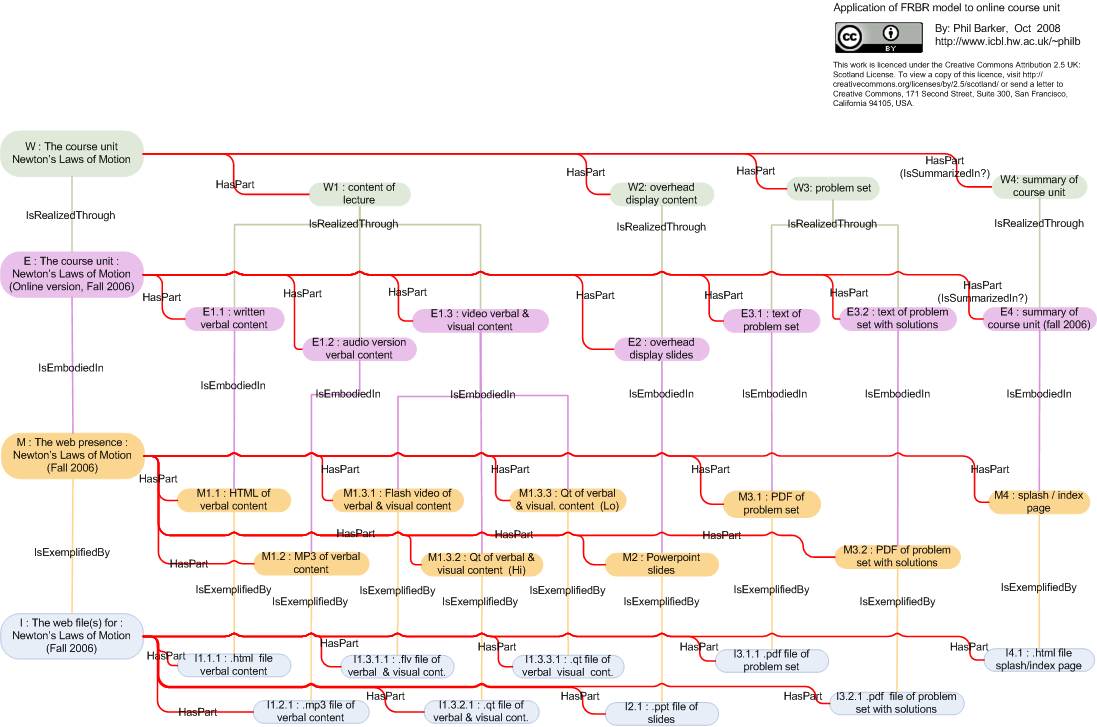
I’ve described the modelling and rationale in some more detail in a separate document [pdf].
I would warmly welcome any comments, suggestions and pointers to where I’ve gone wrong.
OAI-ORE 1.0 released
The first production release of the Open Archives Initiative Object Reuse and Exchange (OAI-ORE) specification was published last Friday (17 Oct). OAI-ORE uses concepts from the web architecture, semantic web, linked data and Atom syndication to expose the relationships between parts of an aggregation, e.g. linked web pages, different formats of the same publication, chapters in an online book, and collections of documents, photos or recordings. OAI-ORE comes from the scholarly publication community, but has wider application: it’s sort of equivalent to parts of the manifest in an IMS Content Package, but with more emphasis on showing relationships between resources on the web and rather than describing what should be in a package and how it should be displayed. Further info: press release [pdf], OAI-ORE specifications.
George Orwell is blogging
George Orwell is blogging, so is Samuel Pepys. And quite aside from the content (I’m an Orwell fan, the merits of this content was discussed when the blog was launched here, and here), I think this is brilliant way of putting diaries online as open content[1]. Delivery, at least, relies on software anyone can use for free[2]; you and I can get the text in a machine readable format, HTML and RSS; each entry gets a URI; the entries can be tagged and commented on; locations can be mapped on Google (Orwell, Pepys), other concepts mentioned linked to encyclopaedia entries; the blog owners could, at least in principle, export the whole lot in XML and stick it in a database to process, and anyone can process entries with text mining software or by setting up a Google custom search engine or . . . .
The two examples above are slightly short of perfect. I like to see the dates for the blog entries matching the dates for the diary entries (the Pepys diaries do this, Orwell managed it at first, but then slipped). And I think it would make more sense if the monthly archives were arranged to be read top-to-bottom in chronological order. Also I wonder if hosting on wordpress.com is the best idea. It has its attractions, but the tags in the Orwell blog link to posts from other blogs which are well out of scope while the Pepys diary has some very interesting customizations; also if the Orwell blog owners do ever find a way to go back to posting against the diary entry date I imagine they would have problems setting up redirects so that links to the current posts still work.
Notes:
1. I guess I should be clear: I’m not saying that these diaries are open content. The Pepys text is from Project Gutenberg, I don’t know the licensing arrangements for other aspects of the blog; Orwell’s text is still copyright in many countries (including the UK and the US), I don’t the licensing arrangements for the blog.
2. The Orwell diary is on WordPress.com; Pepys uses a customized installation of Moveable Type.
An update on DCMI Education work
I was lucky enough to go to Berlin for the DC2008 Dublin Core Metadata Initiative conference. My reasons for going were two-fold: firstly we were presenting a poster, about which John has written; secondly there were some workshop sessions related to education metadata.
Me gusta “Agrega”
I’ve just come across Agrega, a Spanish learning object repository, and my first impressions are that there is a lot about it that I like–for me it has kind of set a benchmark to judge the new Jorum services by when it launches. Continue reading
Repository fringe videos online
Video recordings of presentations from this August’s “repository fringe” in Edinburgh are now available online at http://www.repositoryfringe.org/. From what I’ve heard of the event (I was out of Edinburgh when it happened) the bulk of the event took “repository” to mean “repository of research outputs”, which often seems to be the case, but there’s a recording of Sarah Currier, of Intrallect talking about web services and open access to learning and research materials, and find it’s always interesting to follow what people like Dorthea Salo have to say about their experience of running institutional repositories of research output and think about how it might apply to similar effort to collect teaching and learning materials. It’s also interesting to see the research-output people move into areas like sharing data or alternatives to academic papers as outputs, where I think they might meet some similar cultural issues to those we have when managing and sharing learning materials.
Many thanks to the people who organized this meeting and made the videos available.
Why share?
In a comment to a previous post of mine, Gayle reminded me of the point made by the ACETS project:
“Re-use is not in itself a good or bad thing and it should not be encouraged or discouraged as a matter of dogma. Rather it should be nurtured and supported where it can provide benefits and not where it will not.â€
So the question we should ask is: when will re-use provide benefits? Here are some links to recent and ongoing work relating to the benefits of sharing, reuse and open content.
Continue reading
Linking repositories to VLEs
I’ve made an exploratory start to what I hope will be a new area of work, looking at how repositories containing learning materials and VLEs interact. For some time I’ve been hearing about various projects (some JISC funded, some based at JISC services, some institutional, some commercial) that have the aim of “linking” a repository to a VLE. However I don’t have a clear picture of what is going on overall, and I have a suspicion that maybe other people are in a similar position. I’ld like to discover more detail about what people mean when they say they are “linking” a repository to a VLE.
Continue reading