I’ve written an uncharacteristically long post on my personal blog about online identity and the way I’ve been mashing a whole bunch of things together over there for some time. Is it an e-portfolio? I suppose it must be!

I’ve written an uncharacteristically long post on my personal blog about online identity and the way I’ve been mashing a whole bunch of things together over there for some time. Is it an e-portfolio? I suppose it must be!
I’ve spent the last few hours (after getting home from a swift pint in the pub admittedly) having one of those satisfying coding experiences where the dots just start joining up… I took the very nicely written OpenIDenabled PHP library and bolted it on to the authentication routines for PROD.
The technical principles behind OpenID are simple enough: the user tells your application their openid URL, the app asks the relevant provider if everything is ok, the provider comes back and tells the app a whole bunch of stuff saying that the user is kosher (or halal or whatever it says in their profile).
The latest version of the toolkit made this a breeze – coming as it does with working examples and very well documented code. Most of the work was putting in a few new hooks in my authentication script to catch both ends of the transaction, copying and pasting some code from the example scripts to create the consumer object and set it flying and finally catching the response at the end and telling my application that the user is now logged in.
As with most quick work there is still quite a bit tidying up to do – particularly around how I associate existing users in the LDAP directory with their OpenIDs… At the moment I’m just not bothering. Useful error messages would probably be a good idea too! Testing it with a few different providers is also a must.
One gotcha I discovered was that at some point the exact recipe for doing Delegation must have changed and that the library is more fussy about this than other implementations I’ve seen and used. When testing using my own domain’s delegation which I’ve had set up for years it was consistently failing. This is not good news as there are probably thousands of people who still have it set up exactly as I did…
Another (Ubuntu specific) issue was that it was failing to authenticate against yahoo’s service because I was missing some bits of openssl… This was fixed with a quick sudo apt-get install openssl ca-certificates
Now I’ve had a few brushes in recent months with OpenID mainly around the web provision for the XCRI project – where we got OpenID working across WordPress, Mediawiki, and (through some rather cheap hacking) BBpress. It was however reliant on plugins for said apps and never really a very satisfactory experience – generating a long string of complaints from users getting very variable results depending on which provider they were using. Upgrading any particular component of the site seemed to just lead to more chaos.
Sadly I think that these variable experiences do rather detract from the potential that OpenID has to help us all better manage our online identities. That and the insistence of so many “providers” like Yahoo! and WordPress.com that they are just that, providers and not consumers. I’ve already got about 6 OpenIDs on the go without really realising – useful for testing but the exact opposite of the single authentication service goal. Tsk tsk.
Anyway… Now that I’ve actually tackled the problem at a slightly deeper level I’m feeling confident that over time we can not only iron out XCRI’s woes but also introduce OpenID across the JISC CETIS (and IEC) services in a reasonably robust way. The future looks rosy, the sky is blue, thunderclouds? What thunderclouds?
Some time ago (like about 2 years or so) I had this great idea for an ePortfolio manager that would use timelines and playlists to organise ones life experience and be all superduperly web enabled and so forth. I even gave it a catch name and registered a domain for it: Mofolio

I posted up my mockups and then did absolutely nothing with it! Shame.
Anyway, this idea has been re-surfacing in my mind of late and if it’s not too late to pick it up again I’m going to see if I can make some kind of push into actually building it in the autumn.
The timeline component was something I always though really important to give people a visualisation of their work and experiences and today, while reading Alex Little’s blog I saw his post entitled Time for Timelines where he tries out two tools for doing just this; Simile which is a timeline-generating javascript widget from MIT and the intriguing Dipity which looks like it has beaten me to it in many respects. Dipity takes a bunch of feeds (rss, flickr, blogger, twitter etc etc etc) and turns them into a timeline. You can then add more stuff or remove things or make other timelines about the history of Spacerock in the 1970s or whatever floats your boat. Here’s mine – it took five minutes and for some reason wouldn’t accept my workblog feed. Ho hum:
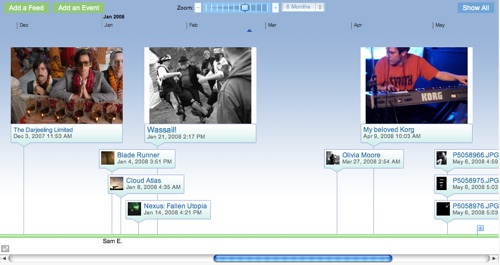
And it wouldn’t embed a live version in WPMU… Click to see the real thing
Anyway this all gives me pause for thought – Mofolio also needs to do much of this, but as I had conceived it, needs to do a whole load more too. Reflection, playlisting, organising of earlier educational experiences, organising of local resources (rather than just webstuff). Oh and it’s got to be prettier and have swimlanes rather than just everything muddled together.
Dipity and other such general timelining tools doubtless also have their classroom use potential. Great for teachers who want to have students build reflective timelines of their learning experiences or timelines representing the rise of the roman empire or whatever it may be. Then again there are always big bits of flip-chart paper and sticky notes.
I’ve been attending a course on The Open Group Architecture Framework or TOGAF down in London. The aim of TOGAF is to provide a methodology for effecting change in the IT capabilities of an organisation by taking a consistent (though perhaps rather top-down) approach to structuring everything through analysing the business needs and processes…
The course run by Architecting the Enterprise was pretty power-point-heavy and by the end of the first day we were all getting pretty sleepy. There was plenty of terrible clip art and bullets bullets bullets. The second day was slightly better as we were all that little bit more awake but still there was a general consensus that the balance could be more on the workshopping of the case-study as a means to teach the method rather than the endless transmission. They are doing the job of giving us an understanding of the methodology – my criticism is simply a question of style.
The first principle of TOGAF is to put in place an architecture process – or Architecture development model – mapping out the business needs, applications, data and infrastructure which go to make things work. Simply thinking about the architecture you’re planning to put in place, who the stakeholders are, scoping it out sensibly, getting the right solutions and planning the migrations in a structured, iterative manner, considering risks etc etc should clearly help organisations to run a more efficient and tight ship in terms of alignment of IT with the actual business needs. The daisy below shows the model, each petal representing a core element of the process, all feeding the central requirements. In this diagram one petal is expanded to show the sub-process within….
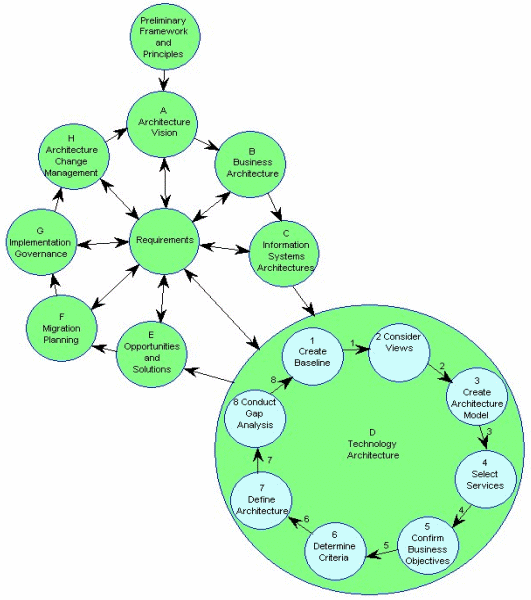
Togaf’s Architechture Development Model (as exploded by developer.com)
The question for us in Education is of course how does this gel with the constraints in which we work – how we get the buy in from both the top and bottom of the organisation to such an approach. Can it be applied in a more light-weight way, how do we deal with the technological shanty-towns that exist in academia. Ultimately we figured out that going through the initial stages of the methodology would probably serve to expose a lot of cultural issues and barriers to change within the organisation.
By way of context, the other participants of the course are mostly working on JISC Enterprise Architecture projects and actually have responsibility for applying these things in their own organisations.
There are a range of certified modelling tools for TOGAF – but it should be noted that there are other “un-certified” tools which could concievably be used to model and manage the togaf process. As ever with these kind of things they will all havetheir specific uses, affordances, personal fans, strengths, weaknesses and so forth. We were not given a specific push towards one tool within the training course but we were given some criteria by which to evaluate them; Core questions – does it support the ADM process, deliverables, models and how the tool handles import/export and extensibility. Most significantly though is probably usability and cost of ownership – which varies wildly across the available products from circa $100 per seat to thousands and thousands.
To be continued…
A year has passed since I started thinking about the redesign of the CETIS website, and inevitably now that the whole thing is creaking into some semblance of what Scott and I had originally intended it has been time to go back to basics and re-examine what we thought we were doing, why we are doing it, whether it is working and what on earth we are going to do next.
There are a few processes going on; Mark, Sharon and Adam have been conducting a review of the community wiki aspects of the web presence and the e-learning focus team are considering where to go next with their magazine-style site with a view to merging it together with the JISC-CETIS page. The Communications team has been discussing the whole show from start to finish and back again.
My thoughts
1) You are in a twisty turny maze
There is a tendancy for people to get lost in the site. Removing some navigational elements (especially in the wiki) and applying some others (breadcrumbs, menus etc) in a coherent way will make a difference I hope – but the main proposal is as follows:
Merge the www.cetis page, the jisc.cetis page and the elearning focus site into one coherent magaziney all-singing portal.
The mockup (v3) shows the main elements we have identified – with a monthly editorial, regularly changing “features”, and constantly changing “news”. It also gives prominence to the SIGs with a prominent bar on the left hand side…
To start off with, the news and features would actually be drawn from the blogs as the current aggregation is – only the editiorial process will be stepped up – with lead-ins and article filtering-selection done by the focus team. As is done with e-learning focus, articles may also be commissioned by external writers.
V2 has a horizontal-slice approach; Banners | Navigation | Editorial | News etc (3 streams) | Other stuff (4 streams)
V1 is an earlier attempt – and is more like the aggregation as it stands at the moment.
2) Re-work the SIG entry points
We made a decision quite early on that the SIGs would simply have a protected wiki page each to serve as their main site – giving them total flexibility to do whatever they wanted. Of course this approach led to inconsistency and an extra learning curve for staff. The result was certainly not easy to follow for the outside observer and generally quite unsatisfactory to my mind.
sig-page.pdf
I have in fact started working on it
So the plan would be coherent entry points combining the main details of the sig, good quality linkage with the events system and drawing in content from the main aggregation and wiki (by tag naturally). Crucially the co-ordinators need customisable space to do with what they wish whether it be posting up some powerpoints or pointing to some interesting resources online somewhere – I need another pass of Mark and Sharon’s work as well as a round of discussion with co-ordinators to figure out exactly what really needs to be done.
3) The project tracker
Already discussed somewhat in my post about doap and ohloh I have a chunk of time set aside for re-working the project tracking system so we can reliably keep tabs on what is going on with JISC projects. Again this needs to be nicely integrated.
One last thing
There is one last thing. I propose removing all traces of rounded corners in favour of the infinitely superior square corners. Trendy design at it’s best don’t you think ![]()
I’ve been at the JISC Conference in Birmingham. I skipped the opening keynote opting to sit around the CETIS stand talking to colleagues (wilbert/oleg/paul/osswatch etc) including discussing the potential for an improved project tracking system based on DOAP and what to do with the old e-Learning Framework – all of which is completely part of my work-plan for the next six months.
I mooched around the stands – picking up several good things like a small rubber armchair and a neat little 4-port USB hub. Thanks to the exhibitors whoever you are… but I then went and left the bag of goodies on a train! How silly is that. Fortunately it didn’t have anything of real importance inside.
The first session I went to was on The learners experience of elearning. Based on two ‘big’ studies it examined learners and their use of and attitudes toward learning technologies. The session felt like somewhat of a bedding down into the web2 mould – acknowledging that learners are mostly streets ahead of institutions in terms of their demand for online services as illustrated through blogs, myspace, msn, faceparty and that subverting these to educational ends is simply happening naturally.
One institution which has taken the bull by the horns and provided collaborative eportfolio-blogging services for the student body is Wolverhampton – through their use of Pebblepad. Emma Purnell, one of their recently qualified PGCE students came along to tell us all how she had caught the eportfolio bug and how it changed her learning – watch the video if you dare!
Next up, I went to a session about OpenAthens. In case anyone doesn’t know Eduserv is a firm charity which provides the Athens authentication service to many educational institutions and organisations, mainly in the UK. The commercial and open-source worlds are starting to get on their own personal identity bandwagons with offerings such as OpenID and Windows CardSpace. To deal with all this Eduserv have cooked up a framework of their own which (for fairly obvious reasons) they have called OpenAthens. It’s a re-working of their existing software and services only designed to work in a more heterogeneous environment. It includes libraries and plugins for client applications, administrative tools and plugable back-end services capable of interfacing with all sorts of different federations and federation methods including Shib, OpenID and all the rest of them. By all accounts it sounds pretty neat. The session was supposed to be a workshop and I thought they might just do a real demo to show how it works… but no this is another death-by-powerpoint moment. They did however point to their developer site http://labs.eduserv.org.uk/aim/ for us to glean the full gorey details.
Finally the inspirational talk of the day was given by Tom Loosemore from the BBC. He runs their whole online operation by the sound of it and mercifully sounds like he really has his head screwed on. He outlined the scale of the BBCs electronic empire (thousands of sites) and took us through the 15 most important things you need to know about the web. It’s always heartening when someone just talks common sense and you can almost hear everyone in the room go “oh my, of course, how sensible”. You can of course read the commentary and see his 15 important things for yourself. Or read his blog which is currently violating rule #8 – hopefully to be rectified soon.
Walking along the River Thames this morning to the ePortfolio 2006 Plugfest in the middle of a serious thunderstorm was perhaps not the smartest of plans – but it didn’t take too long to dry out. I attended the plugfest last year and it was excellent, the day was packed with demos and slinging around of data between a variety of eportfolio solutions and this year it was just as interesting.
ePortfolio Systems Integration
This session follows on from the previous year where there was a lot of focus on using xml (mainly IMS-ePortfolio and IMS-LIP) to move portfolio data from one system to another. Only this time the collection of standards has expanded to cover HR-XML and Europass initiatives.
We started off with ePet and EPICS projects – the projects are based in the north-east of England and in use at Newcastle University as well as several other HE and FE institutions in the region. They have been using IMS-LIP for data transfer – which was demonstrated last year, but have now added Europass XML to the list of capabilities – for both import and export of data.
KiteCV is a plugin to add eportfolio creation and export capabilities to several other systems; wordpress, elgg and dotclear. I had a good go with this particular tool (compiling it on my Mac with the developers looking over my shoulder) and indeed it successfully created a europass conformant CV from within WordPress. Using it as a plugin though feels slightly odd – yes it lets youembedd a CV within a blog entry but I’m just not sure why you might wish to do that!
Selwyn from Phosphorix showed iomorph, a generic transformation engine for they have added europass – hr-xml to their list of available formats (the officially supported list is IMS-Lip, UKLEAP, and XCRI – but the toolkit is also capable of supporting custom xslt transforms and CSV data). For the demo they took the newcastle data in hr-xml format into their icebox system – merrily generating nicely formatted CVs.
Giunti Labs stepped up with exact Portfolio – trying to import and export IMS eportfolio. This wasn’t so successful however they assured us that it did work and that they are working on creating plugins and transforms to get the data in and out of other formats too.
Pebblepad (and their lovely flash-based interfaces) showed their export cv functionality. A user chooses one of their many cvs (they can of course generate them for different purposes) and dumps it out in some exchangable format. Their focus is on making all the technicalities as invisible to users as possible – so importing a webfolio from an external site is just a matter of pasting in the url and the software does the rest.
This got me thinking – how do you expose and discover an eportfolio on a public website – could it not be done in the same way as RSS feeds are exposed on via link-rel tags? Perhaps one to develop for next year.
Sarah Davies from JISC asked a sensible question as to what happens if the concepts don’t map? If one system does actionplans and someone else does goalplanners – the fields encoded in the xml _should_ map sensibly even if the semantic meaning is slightly different – but the general consensus was that your milage may vary.
Sample xml files from this part of the plugfest are all available on the eifel website.
The main event of my week was the CAA Conference in Loughborough. I’m rather amazed that in all my years of being involved with assessment from the days of Canvas onwards I’ve never managed to go to this conference before. There was not only some interesting stuff going in terms of content on but the entertainment laid on by the organisers (and bankrolled by Questionmark) made it really quite special. They took us on a steam train from Loughborough up to somewhere near Leicester, with dinner and a murder-mystery along the way.
My conference highlights included:
* A chap from Macedonia who is creating a SOA-based assessment system
* A demo of BTL Content Producer (which is being used by the SQA)
* A demo of EXAM-4, a tool for performing high stakes exams on unsecured laptops
* Question Buddy
* A long chat with a chap from Wolverhampton about open-source student record systems, and the evils of SITS…
Then I noticed that the servers were down again – and spent much of wednesday morning frantically skypeing MarkP to try and get them working again. See full explanation in entry to follow.
I stood up during the JISC session on day 2 to do a very terse overview of the e-framework, the toolkits, how wonderful FREMA is for the assessment end of it, and a general plug for CETIS and the SIGs and what we do. This seemed to go down fine.