Last Friday I attended one the current series of Talis platform days in Manchester. The days are designed to give an introduction to linked data, how to work with open data sets and show examples of linked data in action from various sources including Talis.
In the morning the Talis team gave us overview of linked data principles, the Talis platform itself and some real life examples of sites they have been involved in. A couple of things in particular caught my attention including FanHubz . This has been developed as part of the BBC backstage initiative, and uses semantic technologies to surface and build communities around programmes such as Dr Who.
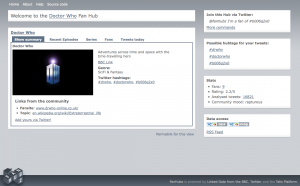
It did strike me that we could maybe start to build something similar for JISC programmes we support by using the programme hash tag, project links, and links from our PROD database (now Wilbert is beginning to semantify it!). This idea also reminded me of the Dev8 happiness rating.
Leigh Dodds gave a comprehensive overview of the Talis platform which you can free account for and play around with. The design principles are solid and it is based on open standards with lots of restful service goodness going on. You can find out more at their website.
There are two main areas in the data store, one for unstructured data which is akin to an amazon data store, and one structured triple store area – the metabox. One neat feature of this side of things was the augmented search facility, or as Leigh called it “fishing for data”. You can pipe an existing RSS1.0 feed through a data store and the platform will automagically enrich it with available linked data and pass out another augmented feed. This could be quite handy for finding new resources, and OERs ran through my mind as it was being explained.
The afternoon was given over to more examples of linked data in action, including some Ordinance Survey open maps and genealogy mash-ups leading to bizarre references to Kajagoogoo (and no, I can’t quite believe I’m writing about them either, but hey if they’re in DBpedia, they’re part of the linked data world).
We then had an introductory SPARQL tutorial. Which, mid afternoon on a Friday was maybe a bit beyond me – but I certainly have a much clearer idea of what SPARQL is now and how it differs from other query languages.
If you are interested in getting an overview of linked data, and an overview of SPARQL, then do try and get along to one of these events, but be quick as I think there is only one left in this current series.
Presentations from the day are available online.