In Comparing metadata requirements (part 1) I examined the required and suggested metadata for Open Educational Resources in the UKOER programme, for the Jorum deposit tool, and the DiscoverEd aggregator. In this second part of the comparison I’m going to try to capture some of our initial discussions fom the UKOER programme session about metadata and then very roughly compare the brainstorming we did as part of that event with the requirements of the programme and other initiatives.
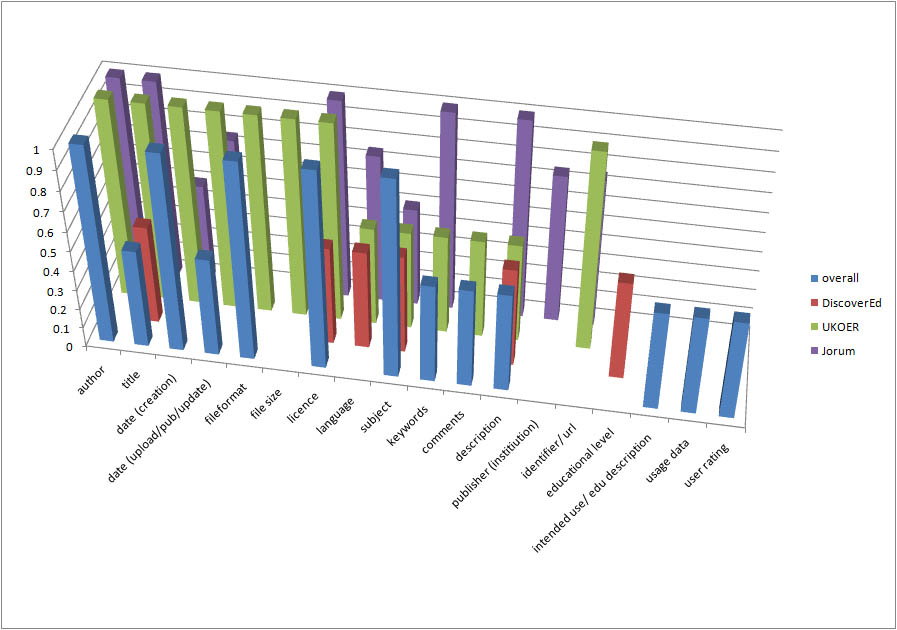
To begin with let’s have a look at a graphical overview of the requirements from the three initiatives. The graph below displays an overview of the metadata requirements of the UKOER programme, the Jorum deposit tool, and the DiscoverEd aggregator service. Full height bars are manadatory elements, three quarter height bars are system generated elements and half height bars are recommended metadata elements.
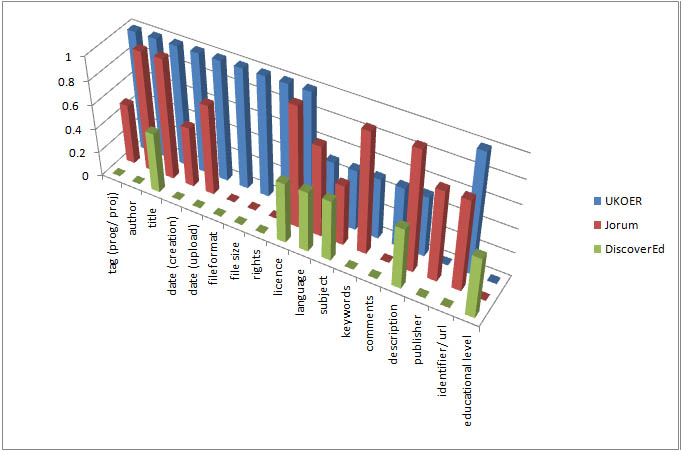
Graphical overview of metadata requirements relating to the UKOER programme
In the elluminate session, we asked the participating projects to consider what metadata they would require to:
- identify
- find
- select
- use
- cite
- manage
a resource. Participants then shared their suggestions in the chat box. I’ve put the data together and were appropriate combined or split entries. The below graph represents the group’s suggestions of which possible pieces of information are important for each of the outlined functions. (Some caveats are in order. The exercise was not rigorous, the number of participants answering at a given time varied; the first question ‘identify’ had a higher broader repsonse rate – this may relate to how we explained the exercise. The answers were free text and not from a prior list. Unless specified the idea of a date is counted for both creation/ initial use and upload/ publication. It also became clear that for functional purposes rights mostly collapsed in to licence (thus it was dropped from the graph).
Condensed outputs of metadata responses
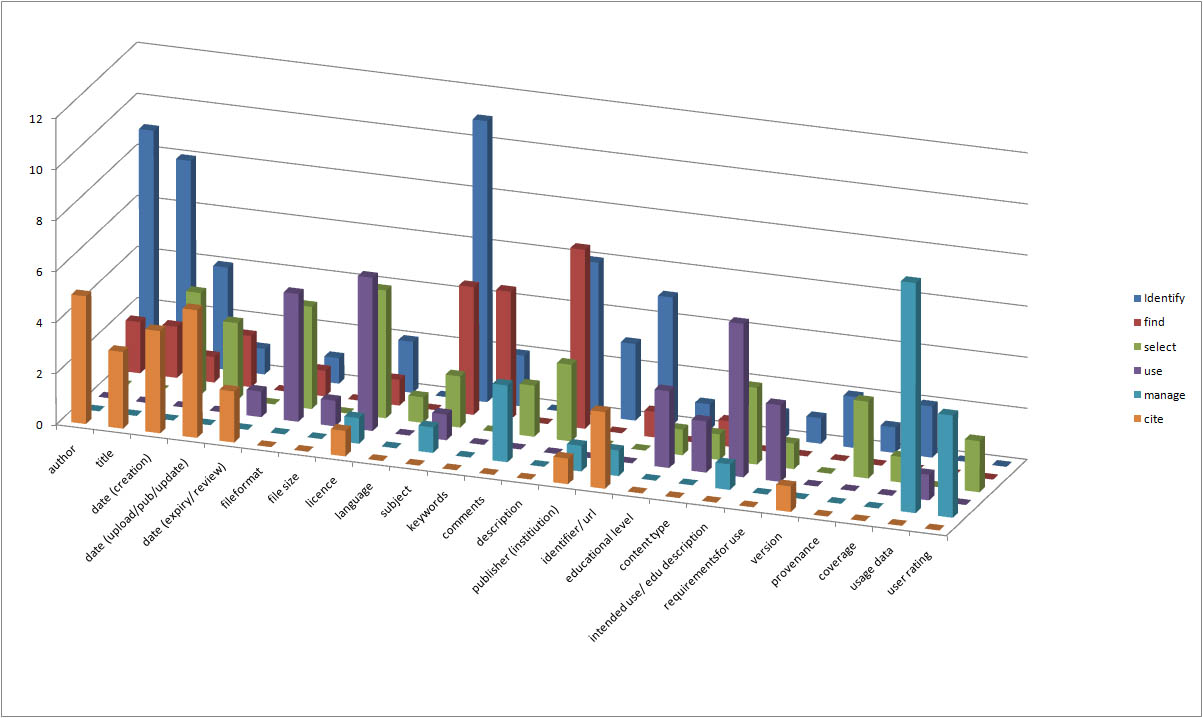
Graph displaying a summary of metadata requirements for functions from brainstorming in 2nd Tuesday session
The idea of educational level is implict in educational description /context and so it should probably be included with that category (this has not been done in this graph however, as educational level is singled out in the requirements). It is not entirely clear what was intended by some of the descriptions – e.g. coverage.
Examining the graph it is clear that there are some key pieces of infromation for particular uses. Across the entire set of functions the key information appears to be: author, date of publication, subject and description, educaitonal description/ intended use (if combined with educational level) and usage data.
The key information for each function was:
- identify – subject
- find – description
- select – licence
- use – licence
- cite – date of publication
- manage – usage data
By way of enabling a comparison with the metadata requirements, the top three responses for each function where collated (and then taken as factor of one) – this was done to provide an approximate indication of overall importance that could be compared to the requirements data.
OER required metadata compared to brainstorming
From this comparison it is interesting to note the following:
- Of the two contentious mandatory metadata elements: file format/ mime type was actually considered to be functionally important.
- Recording the Language of an OER was not considered to be critcial for any of the functions – though all the initiatives consider it important (this may be attributable to the programme-based context of our discussion).
- The institution/ publisher is surprisingly unimportant functionally (unless you are, like Jorum, hosting materials).
- Licence is probably the most important piece of information for an OER.
- Usage data and user ratings are considered to be critical pieces of information – they are not however included in metadata profiles – however, it is likely that this information would be generated over time by the relevant host services
There’s probably more to say about this data and more to do with it but for now at least – that’s plenty to reflect on.