I was really encouraged to hear from our CETIS13 keynote speaker Patrick McAndrew that next week’s OER13 conference in Nottingham is shaping up to be the biggest yet. In our Open Practice and OER Sustainability session Patrick mentioned that the organising committee had expected numbers to be down from last year as the 2012 conference had been run in conjunction with OCWC and attracted a considerable number of international delegates and UKOER funding has come to an end. In actually fact numbers have risen significantly. I can’t remember the exact figure Patrick quoted but I’m sure he said that over 200 delegates were expected to attend this year. This is good news as it does rather suggest that the UKOER programmes have had some success in developing and embedding open educational practice. It’s also good new for us because CETIS are presenting three (count ‘em!) presentations at this year’s conference :}
The Learning Registry: social networking for open educational resources?
Authors: Lorna M. Campbell, Phil Barker, CETIS; Sarah Currier, Nick Syrotiuk, Mimas,
Presenters: Lorna M. Campbell, Sarah Currier
Tuesday 26 March, 14:00-14:30, Room: B52
Full abstract here.
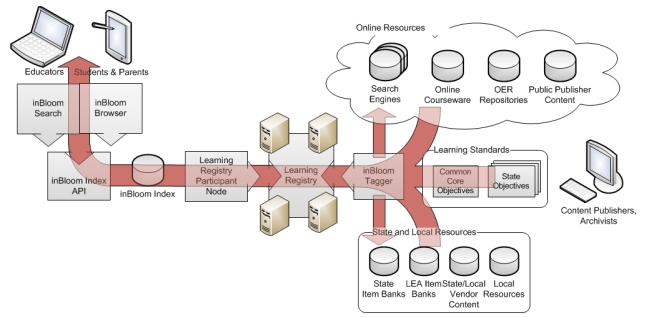
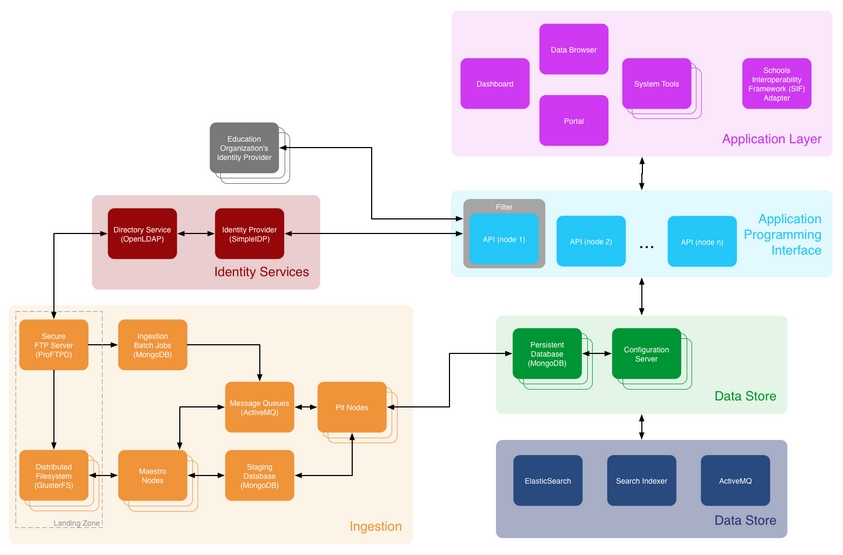
This presentation will reflect on CETIS’ involvement with the Learning Registry, JISC’s Learning Registry Node Experiment at Mimas (The JLeRN Experiment), and their potential application to OER initiatives. Initially funded by the US Departments of Education and Defense, the Learning Registry (LR) is an open source network for storing and distributing metadata and curriculum, activity and social usage data about learning resources across diverse educational systems. The JLeRN Experiment was commissioned by JISC to explore the affordances of the Learning Registry for the UK F/HE community within the context of the HEFCE funded UKOER programmes.
An overview of approaches to the description and discovery of Open Educational Resources
Authors: Phil Barker, Lorna M. Campbell and Martin Hawksey, CETIS
Presenter: Phil Barker
Tuesday 26 March, 14:30-15:00, Room: B52
Full abstract here.
This presentation will report and reflect on the innovative technical approaches adopted by UKOER projects to resource description, search engine optimisation and resource discovery. The HEFCE UKOER programmes ran for three years from 2009 – 2012 and funded a large number and variety of projects focused on releasing OERs and embedding open practice. The CETIS Innovation Support Centre was tasked by JISC with providing strategic advice, technical support and direction throughout the programme. One constant across the diverse UKOER projects was their desire to ensure the resources they released could be discovered by people who might benefit from them -i f no one can find an OER no one will use it. This presentation will focus on three specific approaches with potential to achieve this aim: search engine optimisation, embedding metadata in the form of schema.org microdata, and sharing “paradata” information about how resources are used.
Writing in Book Sprints
Authors: Phil Barker, Lorna M Campbell, Martin Hawksey, CETIS; Amber Thomas, University of Warwick.
Presenter: Phil Barker
Wednesday 27 March, 11:00-11:15, Room: A25
Full abstract here.
This lightning talk will outline a novel approach taken by JISC and CETIS to synthesise and disseminate the technical outputs and findings of three years of HEFCE funded UK OER Programmes. Rather than employing a consultant to produce a final synthesis report, the authors decided to undertake the task themselves by participating in a three-day book sprint facilitated by Adam Hyde of booksprints.net. Over the course of the three days the authors wrote and edited a complete draft of a 21,000 word book titled “Technology for Open Educational Resources: Into the Wild – Reflections of three years of the UK OER programmes”. While the authors all had considerable experience of the technical issues and challenges surfaced by the UK OER programmes, and had blogged extensively about these topics, it was a challenge to write a large coherent volume of text in such a short period. By employing the book sprint methodology and the Booktype open source book authoring platform the editorial team were able to rise to this challenge.