There have been a number of reports in the tech press this week about inBloom a new technology integration initiative for the US schools’ sector launched by the Shared Learning Collective. inBloom is “a nonprofit provider of technology services aimed at connecting data, applications and people that work together to create better opportunities for students and educators,” and it’s backed by a cool $100 million dollars of funding from the Carnegie Corporation and the Bill and Melinda Gates Foundation. In the press release, Iwan Streichenberger, CEO of inBloom Inc, is quoted as saying:
“Education technology and data need to work better together to fulfill their potential for students and teachers. Until now, tackling this problem has often been too expensive for states and districts, but inBloom is easing that burden and ushering in a new era of personalized learning.”
This initiative first came to my attention when Sheila circulated a TechCruch article earlier in the week. Normally any article that quotes both Jeb Bush and Rupert Murdoch would have me running for the hills but Sheila is made of sterner stuff and dug a bit deeper to find the inBloom Learning Standards Alignment whitepaper. And this is where things get interesting, because inBloom incorporates two core technologies that CETIS has had considerable involvement with over the last while, the Learning Registry and the Learning Resource Metadata Initiative, which Phil Barker has contributed to as co-author and Technical Working Group member.
I’m not going to attempt to summaries the entire technical architecture of inBloom, however the core components are:
- Data Store: Secure data management service that allows states and districts to bring together and manage student and school data and connect it to learning tools used in classrooms.
- APIs: Provide authorized applications and school data systems with access to the Data Store.
- Sandbox: A publicly-available testing version of the inBloom service where developers can test new applications with dummy data.
- inBloom Index: Provides valuable data about learning resources and learning objectives to inBloom-compatible applications.
- Optional Starter Apps: A handful of apps to get educators, content developers and system administrators started with inBloom, including a basic dashboard and data and content management tools.
Of the above components, it’s the inBloom index that is of most interest to me, as it appears to be a service built on top of a dedicated inBloom Learning Registry node, which in turn connects to the Learning Registry more widely as illustrated below.
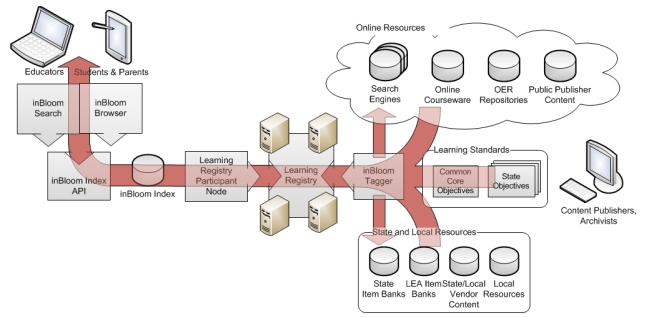
inBloom Learning Resource Advertisement and Discovery
According to the Standards Alignment whitepaper, the inBloom index will work as follows (Apologies for long techy quote, it’s interesting, I promise you!):
The inBloom Index establishes a link between applications and learning resources by storing and cataloging resource descriptions, allowing the described resources to be located quickly by the users who seek them, based in part on the resources’ alignment with learning standards. (Note, in this context, learning standards refers to curriculum standards such as the Common Core.)
inBloom’s Learning Registry participant node listens to assertions published to the Learning Registry network, consolidating them in the inBloom Index for easy access by applications. The usefulness of the information collected depends upon content publishers, who must populate the Learning Registry with properly formatted and accurately “tagged” descriptions of their available resources. This information enables applications to discover the content most relevant to their users.
Content descriptions are introduced into the Learning Registry via “announcement” messages sent through a publishing node. Learning Registry nodes, including inBloom’s Learning Registry participant node, may keep the published learning resource descriptions in local data stores, for later recall. The registry will include metadata such as resource locations, LRMI-specified classification tags, and activity-related tags, as described in Section 3.1.
The inBloom Index has an API, called the Learning Object Dereferencing Service, which is used by inBloom technology-compatible applications to search for and retrieve learning object descriptions (of both objectives and resources). This interface provides a powerful vocabulary that supports expression of either precise or broad search parameters. It allows applications, and therefore users, to find resources that are most appropriate within a given context or expected usage.
inBloom’s Learning Registry participant node is peered with other Learning Registry nodes so that it can receive resource description publications, and filters out announcements received from the network that are not relevant.
In addition, it is expected that some inBloom technology-compatible applications, depending on their intended functionality, will contribute information to the Learning Registry network as a whole, and therefore indirectly feed useful data back into the inBloom Index. In this capacity, such applications would require the use of the Learning Registry participant node.
One reason that this is so interesting is that this is exactly the way that the Learning Registry was designed to work. It was always intended that the Learning Registry would provide a layer of “plumbing” to allow the data to flow, education providers would push any kind of data into the Learning Registry network and developers would create services built on top of it to process and expose the data in ways that are meaningful to their stakeholders. Phil and I have both written a number of blog posts on the potential of this approach for dealing with messy educational content data, but one of our reservations has been that this approach has never been tested at scale. If inBloom succeeds in implementing their proposed technical architecture it should address these reservations, however I can’t help noticing that, to some extent, this model is predicated on there being an existing network of Learning Registry nodes populated with a considerable volume of educational content data, and as far as I’m aware, that isn’t yet the case.
I’m also rather curious about the whitepaper’s assertion that:
“The usefulness of the information collected depends upon content publishers, who must populate the Learning Registry with properly formatted and accurately “tagged” descriptions of their available resources.”
While this is certainly true, it’s also rather contrary to one of the original goals of the Learning Registry, which was to be able to ingest data in any format, regardless of schema. Of course the result of this “anything goes” approach to data aggregation is that the bulk of the processing is pushed up to the services and applications layer. So any service built on top of the Learning Registry will have to do the bulk of the data processing to spit out meaningful information. The JLeRN Experiment at Mimas highlighted this as one of their concerns about the Learning Registry approach, so it’s interesting to note that inBloom appears to be pushing some of that processing, not down to the node level, but out to the data providers. I can understand why they are doing this, but it potentially means that they will loose some of the flexibility that the Learning Registry was designed to accommodate.
Another interesting aspect of the inBloom implementation is that the more detailed technical architecture in the voluminous Developer Documentation indicates that at least one component of the Data Store, the Persistent Database, will be running on MongoDB, as opposed to CouchDB which is used by the Learning Registry. Both are schema free databases but tbh I don’t know how their functionality varies.
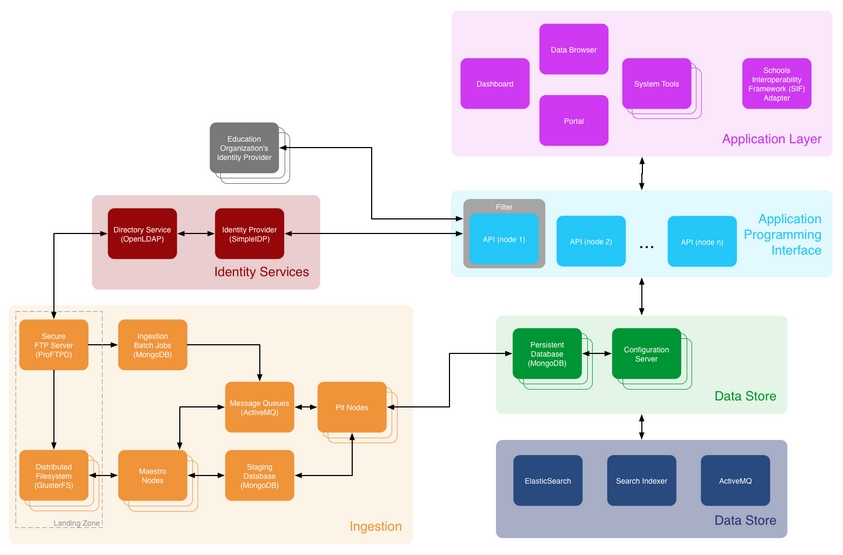
inBloom Technical Architecture
In terms of the metadata, inBloom appears to be mandating the adoption of LRMI as their primary metadata schema.
When scaling up teams and tools to tag or re-tag content for alignment to the Common Core, state and local education agencies should require that LRMI-compatible tagging tools and structures be used, to ensure compatibility with the data and applications made available through the inBloom technology.
A profile of the Learning Registry paradata specification will also be adopted but as far as I can make out this has not yet been developed.
It is important to note that while the Paradata Specification provides a framework for expressing usage information, it may not specify a standardized set of actors or verbs, or inBloom.org may produce a set that falls short of enabling inBloom’s most compelling use cases. inBloom will produce guidelines for expression of additional properties, or tags, which fulfill its users’ needs, and will specify how such metadata and paradata will conform to the LRMI and Learning Registry standards, as well as to other relevant or necessary content description standards.
All very interesting. I suspect with the volume of Gates and Carnegie funding backing inBloom, we’ll be hearing a lot more about this development and, although it may have no direct impact to the UK F//HE sector, it is going to be very interesting to see whether the technologies inBloom adopts, and the Learning Registry in particular, can really work at scale.
PS I haven’t had a look at the parts of the inBloom spec that cover assessment but Wilbert has noted that it seems to be “a straight competitor to the Assessment Interoperability Framework that the Obama administration Race To The Top projects are supposed to be building now…”