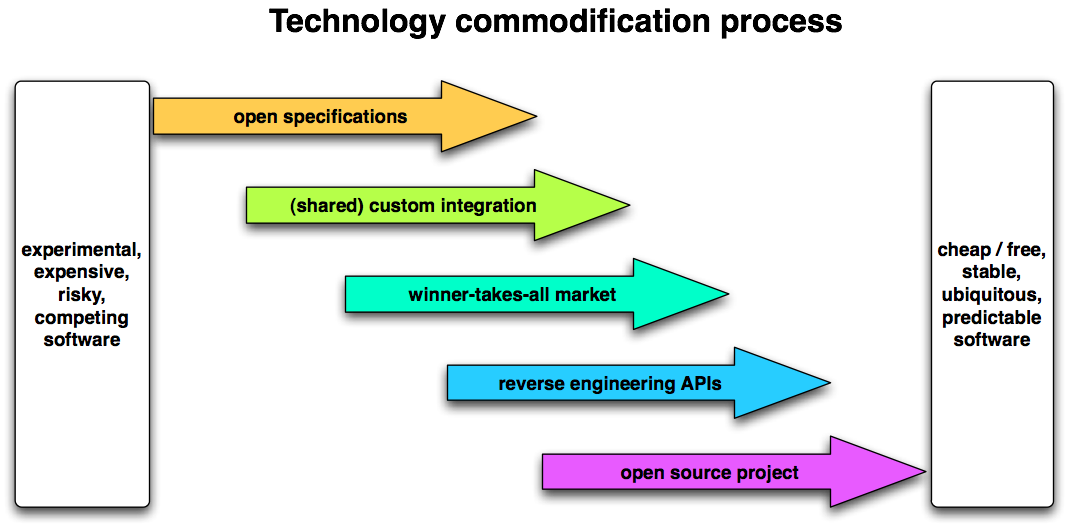
In the twelve years of its existence, an awful lot has been learned about interoperability by IMS staff and members. This is nowhere more apparent than in the most quintessentially educational of interoperability standards: question and test items (QTI). A recent public spat about the IMS QTI specification provides an interesting contrast to two emerging views of how to achieve interoperability. Fortunately for QTI, they’re not incompatible with each other.
Under the old regime, the way interoperability was achieved was by establishing consensus among the largest number of stakeholders possible, create a spec, publish it and wait for the implementations to follow. With the benefit of hindsight, it’s fair to say that the results have been mixed.
Some IMS specs got almost no implementation at all, some galvanised a lot of development but didn’t reach production use, and some were made to work for particular communities by their particular communities. On the whole, many proved remarkably flexible in use, and of sound technical design.
Trouble was, more often than not, two implementations of the same IMS spec were not able to exchange data. To understand why, the QTI spec is illustrative, but not unique.
For a question and test spec to be useful to most communities, and for several of these communities to be able to share data or tools, a reasonably wide range of types needs to be supported. QuestionMark (probably the market leader in the sector) uses the wide range of question types that its product supports as a key differentiator. Likewise, though IMS QTI 2.1 is very expressive, a lot of practitioners in the CETIS Assessment SIG frequently discuss extensions to ensure that the specification meets their needs.
The upshot is that QTI 2.1 is implementable, as a fair old list of tools on wikipedia demonstrates, but implementing all of it isn’t trivial. This could be argued to be one reason why it is not in wider use, though the other reason might well be that QTI 2.1 was never released as a final specification, and now is no longer accessible to non-IMS members.
To see how to get out of this status quo, the economics of standard implementation need to be considered. From a vendor’s point of view – open or closed source – , implementing any interoperability spec represents a cost. The more complex and flexible the specification, the higher that cost is. This is not necessarily a problem, as long as the benefit is commensurate. If either the market is large enough, or else the perceived value of the spec high enough for the intended customers to be willing to pay more, the specification will be economically viable.
Broadly two models of interoperability can be used to figure out a way to make a spec economically viable, and which you go for largely depends on your assumptions about the technical architecture of the solution.
One model assumes that all implementations of a spec like QTI are symmetrical and relatively numerous. Numerous as in certainly more than two or three, and possibly double digits or more, and systems as in VLEs. With that assumption, the QTI situation needs clear adjustment. The VLE market is not that large to begin with, and is fairly commoditised. There is little room for investment, and there has not been a demonstrated willingness to pay for extended interoperable question and test features.
From the symmetrical perspective, then, the only way forward is to simplify the spec down to a level that the market will bear, which is to say, very simple indeed. Since, as we’re already seeing with the QTI 1.2 profile in Common Cartridge, it is not possible to satisfy all communities with the same small set of question and test items, there will almost certainly need to be multiple small profiles.
There are several problems with such an approach. For one, reducing the feature set to the lowest cost has a linear relation to the value of the feature set to the end user. Beyond a minimum it might be almost useless. Balkanising the spec’s space to several incompatible subsets is likely to exacerbate this; not just for end-users, but also tool and content vendors.
What’s worse, though, is that the underlying assumption is wrong. Symmetrical interoperability doesn’t work. To my knowledge, and I’d love to be corrected, there are no significant examples of an interoperability spec that has significant numbers of independent implementations that happily export and import each others’ data. The task of coordinating the crucial details of the interpretation of data is just too onerous once the number of data sources and targets that a piece of software has to deal with gets into the double digits.
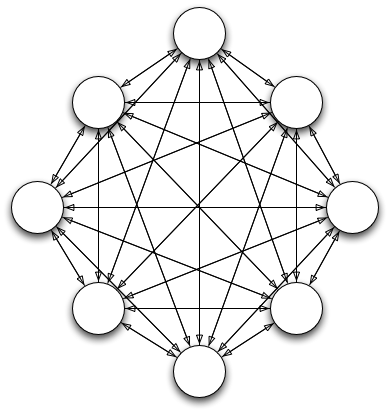
Symetrical, many-to-many interoperability; 8 systems, 56 connections that need to work
Within the e-learning world, SCORM 1.2 (and compatible IMS Content Packages) came closest to the symmetric, many-to-many ideal, but only because the spec was very simple, the volume of the market large, compliance often mandated and calculated into Requests For Proposals (RFPs), and vendors were prepared to coordinate their implementations in numerous plugfests and codebashes as a consequence. Also, ADL invested a lot of money in continuous implementation support. Even then, plenty of issues remained, and, crucially, most implementations were not symmetrical: they imported only. Once the complexity of the SCORM increased significantly with the adoption of Simple Sequencing in SCORM 2004, the many-to-many interoperability model broke down.
Instead, the emergence of solutions like Icodeon’s SCORM 2004 plug-in for VLEs brought the spec back to the norm: asymmetrical interoperability. Under this assumption, there will only ever be a handful of importing systems at most, but a limitless number of data sources. It’s how HTML works on the web: uncountable sources that need to target only about four codebases (Internet Explorer, Mozilla, WebKit, Opera), one of which dominates to such an extent that the others need to emulate its behaviour. Same with JPEG picture rendering libraries, BIND implementations and more. In educational technology it is how Simple Sequencing and SCORM 2004 got traction, and it is starting to look as if it will be the way most people will see IMS Common Cartridge too.
Under this assumption, implementing a rich QTI profile in two or three plug-ins or web services becomes economically much more viable. Not only is the amount of required testing much reduced, the effective cost of implementation is spread out over many more systems. VLE vendors can offer the feature for much less, because the total market has effectively paid for just two or three best-of-breed implementations rather than tens of mediocre ones.
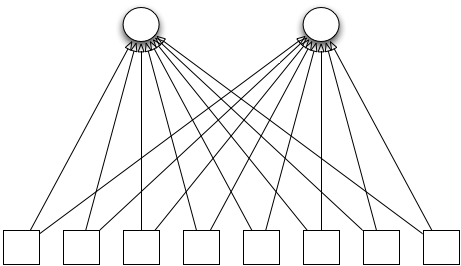
Asymetrical, many-to-many interoperability; 8 source systems, 2 consuming systems, 16 connections that need to work
This is not a theoretic example. Existing rich QTI 2.1 implementations make the asymmetric interoperability assumption. In Korea, KERIS (Korea Education and Research Information Service) is coordinating the development of three commercial implementations of the rendering and test side of QTI, but many specialised authoring tools are envisaged. Likewise, in the UK, two full implementations of the rendering and test management side of QTI exist, but many subject specific authoring tools are envisaged. All existing renderers can be used as a web application, and QTIEngine is also explicitly designed to work as a local plug-in or web service that can be embedded in various VLEs.
That also points to various business models that asymmetric interoperability enables. VLE vendors can focus on the social networking core, and leave the activity specific tools to the specialists with the right expertise. Alternatively, vendors can band together and jointly develop or adopt an open source code library, like the Japanese companies that implemented Simple Sequencing under ALIC auspices, back in the day.
Even if people still want to persist with symmetrical interoperability, designing the specification to accommodate both assumptions is not a problem. All that’s required is one rich profile for the many-to-few, asymmetric assumption, and a very small one for the many-to-many, symmetric assumption. Let’s hope we get both.
Resources
A brief overview of the current QTI 2.1 discussion
Wikipedia’s QTI page, which contains a list of implementations
More on the KERIS QTI 2.1 tools
The QTIEngine demo site
An interview with Kyoshi Nakabayashi, formerly of ALIC, about joint Simple Sequencing implementation work