Project lead: Lisa McLaughlin, Senior Director of Partnerships
“Gooru’s mission is to honor the human right to education. We are dedicated to engaging a community of teachers, developers, and supporters to unleash personalized learning with technology to educate all the students of the world.”
http://www.goorulearning.org/
Gooru serves as a personalized learning platform, incorporating a custom search engine, playlist creation tool, and content aggregator. The system allows users to find standards-aligned, interactive learning materials that have been curated by teachers; share those materials in the form of custom collections, personalized to meet the needs of individual students; and measure students’ progress across collections and quizzes assigned to them. Users can search over 2 million CC licensed learning resources, browse through collections, lessons and individual resources and filter search results by grade level, resource type, and Common Core State Standard.
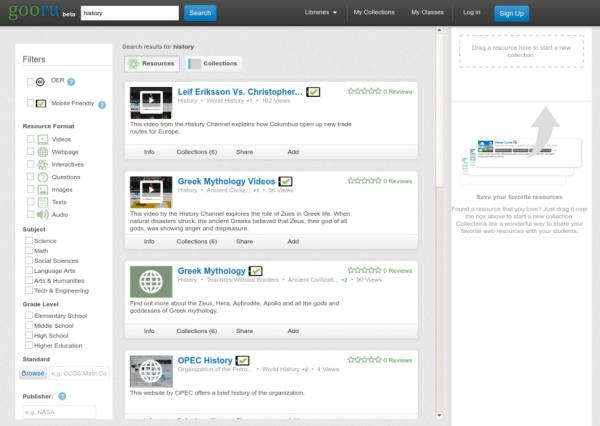
Gooru resource search
Gooru is a repository of playlists, rather than a repository of content. There are currently 18 million resources in the Gooru catalog; 180,000 of these are tagged to instructional standards such as the Common Core State Standards and 50,000 are collections created by teachers and students. Users can also build assessment features into their playlists and the system includes an assessment bank of 1.5 million items. Gooru resources carry a variety of different licences but all are open and free to use. Playlists are currently shared under a CC BY SA licence, however Gooru are in the process of transitioning to CC0 over the course of the next month. Most content is aimed at the K-12 sector.
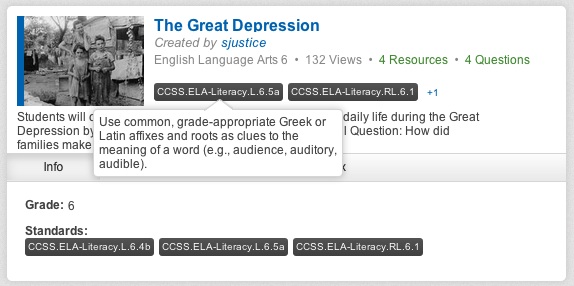
Gooru collection search showing CCSS classification
Gooru has developed an open source learning architecture licensed under the MIT Open Source Initiative approved licence, and a number of APIs that enable developers to build applications based on the Gooru infrastructure. The Gooru APIs are available here: Gooru APIs, and further information about the Gooru development community is available here Gooru Learning Developers.
A custom Gooru Metadata Schema (GMS) composed of 40 fields has been created from various metadata schemas. The Gooru Metadata Schema may be regarded as a variant of the LOM, though to date, GMS has not been mapped directly to LOM. Accessibility Metadata Project fields are used to describe the accessibility of content.
Content with high quality metadata is weighted more heavily in search results, though other factors also come into play, such as how many times a resource is included in other playlists.
Gooru does not ingest metadata through OAI PMH; some metadata is generated by users uploading resources and tagging them using the GMS, but the majority comes from web crawling. Domains are curated through a range of input, both internal and through Gooru’s wider network of partners, before pursuing crawls. Teacher-added domains are prioritized. Basic metadata including title, author, publisher, description, etc is captured from each domain, and then passed to a QA cleaning team, who manually identify more nuanced characteristics, e.g. educational use, time required, etc. For subjective fields, such as educational use, a script has been created for cleaning the metadata. The QA team is currently focused on cleaning the metadata on all OER collections and Gooru recently launched an OER filter.
Metadata fields are currently stored in an SQL database, however Gooru will move to a no-SQL framework later in 2014. Paradata is also stored in similar SQL tables but is returned by different APIs. Only some of the Gooru paradata is currently exposed.
Components of LRMI have been incorporated into the Gooru Metadata Schema and a mapping can be provided from the GMS to LRMI. Approximately 95% of the Gooru catalog is now tagged with LRMI.
The following LRMI properties and types have been implemented and the Gooru LRMI Metadata schema is available here (.xls).
- educationalAlignment
- educationalUse
- timeRequired
- typicalAgeRange
- interactivityType
- learningResourceType
- useRightsUrl
- isBasedonUrl
The GMS includes an Educational Alignment field with alignment types ‘subject’ and ‘educational level’. Alignment type ‘text complexity’ may be added in the future.
In addition to Common Core State Standards, Gooru content is also aligned to Texas Curriculum Standards and California Science Standards
Links
Gooru
Gooru Metadata Guide
Gooru LRMI Metadata Schema


ISKME’s OER Commons offers a comprehensive infrastructure and suite of services for educators globally, including groups of curriculum specialists, administrators, content providers, teachers, librarians, and technology and resource decision-makers who seek to implement high quality and adaptable curriculum through the use, evaluation, and improvement of open educational resources (OER).