What technology is being used to aggregate open educational resources? What role can the subject community play in resources discovery? This is a post in the UKOER 2 technical synthesis series.
[These posts should be regarded as drafts for comment until I remove this note]
In the UKOER 2 programme Strand C funded “Projects identifying, collecting and promoting collections of OER and other material around a common theme” with the aim “…to investigate how thematic and subject area presentation of OER material can make resources more discoverable by those working in these areas” (UKOER 2 call document). The projects had to create what were termed static and dynamic collections of OER. The intent of the static collection was that it could in some way act as an identity, focus, or seed for the dynamic collection. Six projects were funded: CSAP OER, Oerbital, DelOREs, Triton, EALCFO, Open Fieldwork and a range of approaches and technologies was taken to making both static and dynamic collections. The projects are all worth reading about in more detail – however, in this context there are two possible general patterns worth considering.
Technology
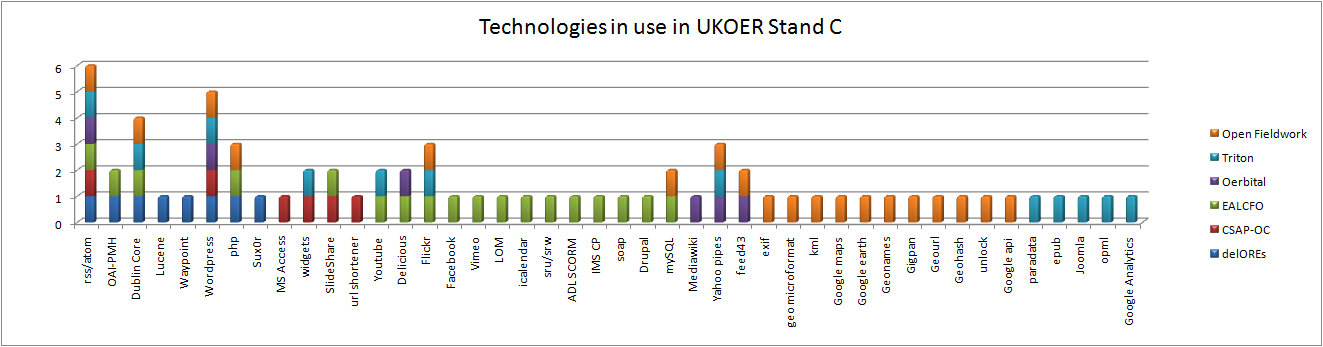
Overview of technical choices in UKOER 2 Strand C
The above graph shows the range of technology used in the Strand. Although a lot could (and should) be said about each project individually when their choices are viewed in aggregate the following technologies are seeing the widest use.
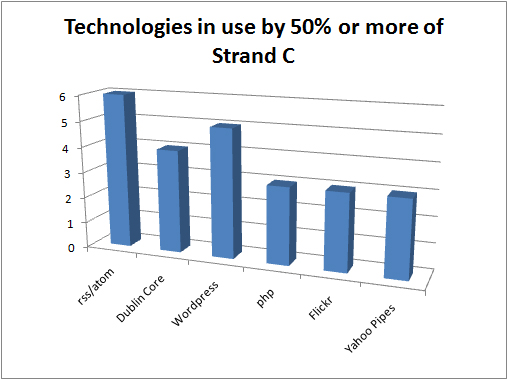
Graph of technologies and standards in us by 50% or more of Strand C projects
Although aspects of the call might have shaped the projects’ technical choices to some extent, a few things stand out:
- the focus on RSS/Atom feeds and tools to manipulate them
- reflection: this matches the approach taken by many of the other aggregators and discovery services for OER and other learning materials as well as the built in capabilities of a number of the platforms in use [nb “syndicated via RSS/Atom” was a programme requirement]
- a relative lack of a use of OAI-PMH
- reflection: is this indicative of how many content providers and aggregators in the learning material’s consume or output OAI-PMH?
- substantial use or investigation of wordpress and custom databases (with php frontends)
- reflection: are repositories irrelevant here because they don’t offer easy ways to add plugins or aggregate others’ content (or are there other factors which make WordPress and a custom database more appealing)
Community
One of the critical issues for all of these projects in the creation of these collections has been the role of community; for some of the strand projects the subject community played a crucial role in developing the static collection which then fed, framed, or seeded the dynamic collection, for other projects the subject community formed the basis of contributing resources to the dynamic collection.
Although the projects had to be “closely aligned with relevant subject or thematic networks – for example Academy Subject Centres, professional bodies and national subject associations” , I find it striking that many of the projects made those defined communities an integral part of their discovery process and not just an audience or defining domain.
Reflections on community
I’m hoping someone else is able to explore the role of community in discovery services more fully (if not I’ll try to come back to this) but I’ve been struck by the model used by some projects in which a community platform is the hook leading to resource discovery. It’s the opposite end of the spectrum to Google – to support discovery you create a place and content accessible and relevant to a specific subject domain. The place you create both hosts new content created by a specific community and serves as a starting point to point to further resources elsewhere (whether those pointers are links, learning pathways, or tweaked plugin searches run on aggregators or repositories). This pattern mirrors any number of thriving community sites (typically?) outside of academia that happily coexist in Google’s world providing specialist sources of information and community portals (for example about knitting, cooking, boardgames).
What it doesn’t mirror is trying to entice academics to use a repository… [I like repositories and think they’re very useful for some things , but this and the examples of layering CMSs on top of repositories, increasingly makes me think that on their own they aren’t a great point of engagement for anybody…]
hmm, have just thought through the implications of separating the Collections strand out… eg use of WordPress in rest of programme is nil. I’m guessing the areas where it will make the biggest difference are platforms and standards time to get back to the data.
Pingback: UKOER 2: Collections, technology, and community | Calling All Lecturers | Scoop.it
CSAP used WordPress as a hybrid tool part blog part collection; OERBITAL used WordPress purely as a blog (after initial consideration of its other possible uses).
Triton used WordPress as a lightweight aggregator of multiple content types (presenting a single interface). Triton finding that there may be a need for some kind of middleware/ directory aggregation function that community portals and services could be built on. CSAP found taxonomy construction required both technical expertise and subject knowledge. OpenFieldwork worked on extracting resources relevant to fieldwork but they found that they had to lots of the tagging and geolocation themselves. OF also displayed spectrum of materials with different licences.
OF also developed traffic light coding for spectrum of resources see interface: http://www.openfieldwork.org.uk/api/
Delores: their static collection was created manually and all openly licensed content (for use as trainer for sux0r). Level of structured resource description within resources made it difficult for automatic classification to work.
OAI-PMH as machine to machine/ repo to repo protocol – it’s a completely different world – diff skills, knowledge, tools from publishing side. OERBITAL didn’t use oai-pmh beyond initial investigation – irrelevant for static collection.
Again perceived need for centralised subject community portal to mediate repository harvesting. Xpert used by most projects – intermediated oai-pmh?
Phil Barker: Harking back to Andy Powell ‘s comment at start of IE architecture 2deposit at an institutional level and discover at a subject level” – is this even more true for OER
CSAP: Role of institution as quality control (vs anyone can deposit); OERBITAL: quality control is highly labour intensive and wading through poor quality resources is demoralizing.
For academics, emerging OER resource discovery tools often compare badly to Google.
Quality review via specialists or at scale? academics are getting used to approximate measures of quality – || to Amazon. Wikipedia now offers opportunity to review pages.
We didn’t use OAI-PMH as there is very little OER in OAI-PMH feeds – at best OERCommons is, and OAI-PMH is usually appallingly slow. So the benefits, if any are incredibly small, and when traded with the speed, it’s not worth the hassle.
The format of OAI-PMH is at best just harder RSS, so an XML parser can do both without worrying too much (it’s not a lot of code, or a time requirement). The issue is as above, there is next to nothing there, and when you do find something, it’s slow, especially if your PHP script only has 30 seconds to run.
A possible omission in this analysis is the difficulty in getting at content, as we partially covered in our blog post – there is no standard API, or approach, or a large enough collection to work with to mean code doesn’t have to be mangled for different approaches. So the lack of OAI, could possibly be perceived as a lack of support for SRU.