or Making finding my way around the UK OER programme one feed at a time a little easier with some help from Yahoo.
In an effort to familarize myself with the OER programme I hunted for project websites and blogs to add their feeds to my netvibes. As not all projects are blogging this is only a partial method of engagement but the mixture of news and discussion of issues on the blogs that exist has helped me begin to find my way around. In the process of doing this I not only found blog rss feeds but one or two feeds of OER resources. Although projects will all be producing RSS feeds for their resources as part of the programme I hadn’t expected to find any yet.
As convenient as this all was now, I still had twenty or so new boxes in netvibes to scan along with all the others. However, one of the things that clearly emerged from the UKOER 2nd Tuesday on metadata that Phil and I ran was that that feeds of resources are going to be very important in this programme. I think we all knew this, and the programme had mandated that projects should produce a feed of their resources, but I was struck by what projects where already doing and some of their future plans. Coming from a repositories background I’ve tended to think of feeds for announcements or, with SWORD, deposit but thought of OAI-PMH or the like for ‘serious’ resource discovery or aggregation. I think OAI-PMH will have a role (and so do CCLearn: http://learn.creativecommons.org/wp-content/uploads/2009/07/discovered-paper-17-july-2009.pdf – more on that another time) but it came home to me how important RSS/Atom is – especially -in an environment were resources are being managed and made available using many different types of software with all that in mind it was time to finally try some pipes..
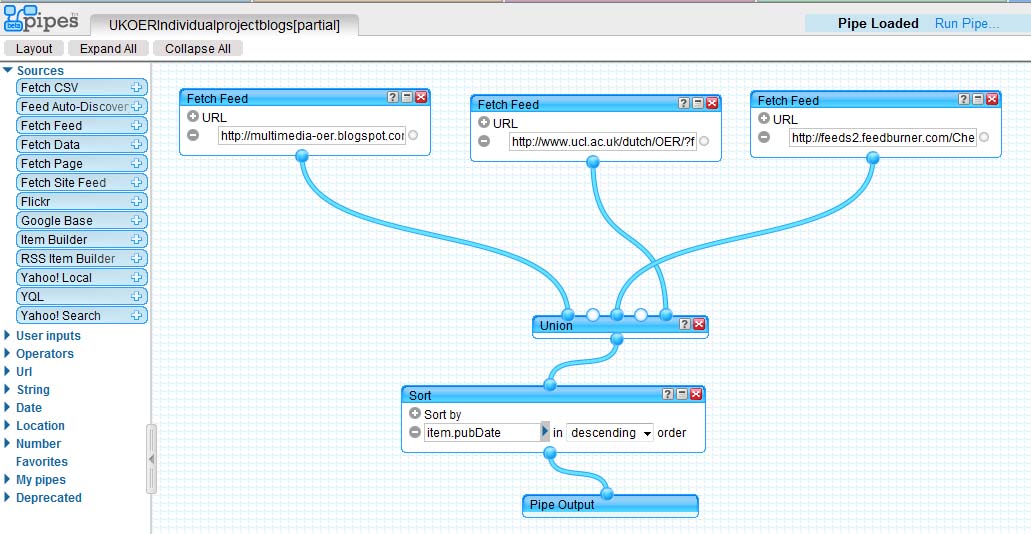
Simple Yahoo pipe of feeds from UKOER Individual strand projects
I pulled together by strand feeds from the project blogs I could find to make these feeds:
Institutional
http://pipes.yahoo.com/pipes/pipe.info?_id=e2288118932fa9ea996b7bb41120cfb7
Subject
http://pipes.yahoo.com/pipes/pipe.info?_id=baef584cd9fcb923605936dea916f47c
Individual
http://pipes.yahoo.com/pipes/pipe.info?_id=422a1e8bbd65b24a12421db4a91e25ee
And then the one feed to rule them all…
http://pipes.yahoo.com/pipes/pipe.info?_id=65080a2934b865342686e96deaf9add3
However, that feed could get quite busy – so for those days when life’s too short to hover over 10 new blog post titles – here a version that only gathers posts with the word metadata associated with them.
http://pipes.yahoo.com/pipes/pipe.info?_id=9bd5e2d97bb3267d52fc7e77103aacdb
It looks a bit like this:
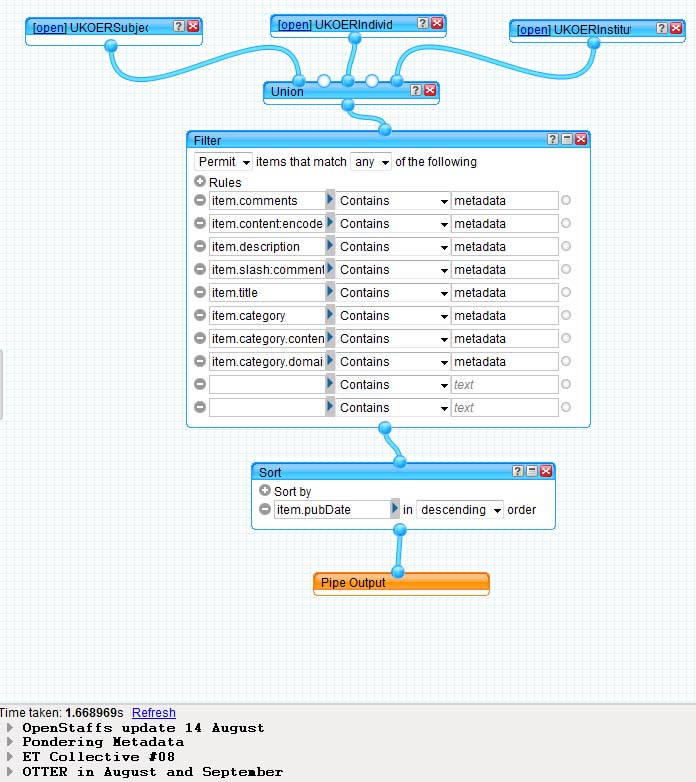
Yahoo pipe for UKOER project blogs with word metadata associated
By the way, for those interested in a feed of UKOER / OER tagged posts from CETIS here’s a feed from our (John, Phil, Li, Lorna, Sheila, Rowin, Scott) blogs http://pipes.yahoo.com/pipes/pipe.info?_id=13b03a2e49b7eb7e7a57d1e1c8961916
With this done I decided to have use the time I’d saved (…) to try something else a pipe for the resource feeds.
http://pipes.yahoo.com/pipes/pipe.info?_id=d93dbd0965e0e9d8399b7818e446b0da
Now I need point out that this last feed is in many ways a ‘toy’ – I don’t know how the resource feeds I’m grabbing have been set up so I don’t know what coverage over time it’ll give. I also know it’s a very poor imitation of the much more careful work done on aggregating by the Steeple project http://www.steeple.org.uk/wiki/Ensemble and Scott in the Ensemble project http://galadriel.cetis.org.uk/ensemble/feeds?q=poetry. One thing I noticed in particular was that the feeds from different software seem to diverge in their use of different metadata fields within RSS.
That said, as of today, my imperfect aggregation is showing 112 OERs so far and the programme’s just getting started.


