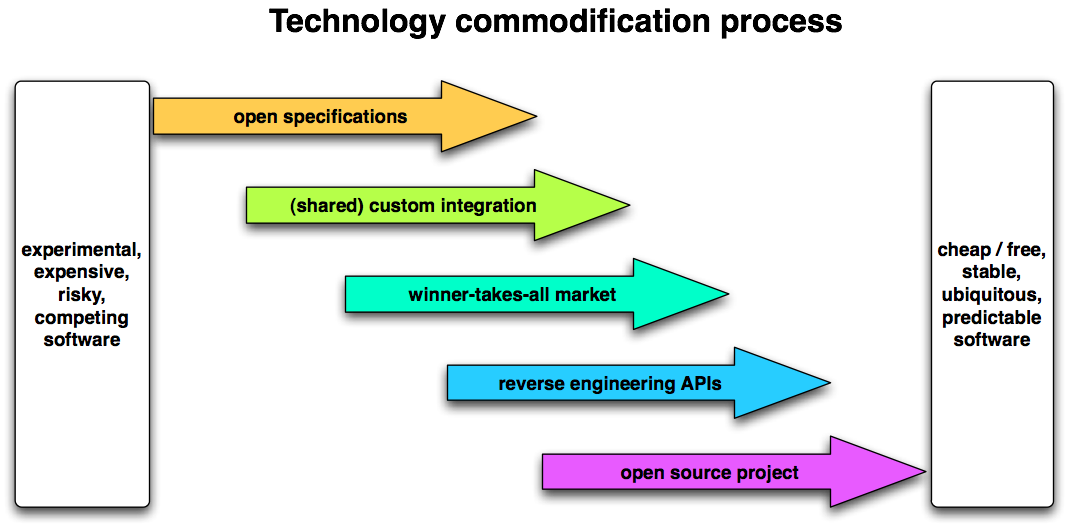
Lots of places and even people have a pile of potentially useful content sitting in a retired CMS or VLE. Or have content that needs to work on a site as much as a pdf or a booklet. Or want to use that great open stuff from the OU, but with a tweak in that paragraph and in the college’s colours, please.
The problem is as old as the hills, of course, and the traditional answer in e-learning land has been to use one of the flavours of IMS Content Packaging. Which works well enough, but only at a level above the actual content itself. That is, it’ll happily zip up webcontent, provide a navigation structure to it and allow the content to be exchanged between one VLE and another. But it won’t say anything about what the webcontent itself looks like. Nor does packaging really help with systems that were never designed to be compliant with IMS Content Packaging (or METS, or MPEG 21 DID, or IETF Atom etc, etc.).
In other sectors and some learning content vendors, another answer has been the use of single source authoring. The big idea behind that one is to separate content from presentation: if every system knows what all parts of a document mean, than the form could be varied at will. Compare the use of styles in MS Word. If you religiously mark everything as either one of three heading levels or one type of text, changing the appearance of even a book length document is a matter of seconds. In single source content systems that can be scaled up to include not just appearance, but complete information types such as brochures, online help, e-learning courses etc.
The problem with the approach is that you need to agree on the meaning of parts. Beyond a simple core of a handful of elements such as ‘paragraph’ and ‘title’, that quickly leads to heaps of elements with no obvious relevance to what you want to do, but still lacking the two or three elements that you really need. What people think are meaningful content parts simply differs per purpose and community. Hence the fact that a single source mark-up language such as the Text Encoding Initiative (TEI) currently has 125 classes with 487 elements.
The spec
The Darwin Information Typing Architecture (DITA) specification comes out of the same tradition and has a similar application area, but with a twist: it uses specialisation. That means that it starts with a very simple core element set, but stops there. If you need to have any more elements, you can define your own specialisations of existing elements. So if the ‘task’ that you associate with a ‘topic’ is of a particular kind, you can define the particularity relative to the existing ‘task’ and incorporate it into your content.
Normally, just adding an element of your own devising is only useful for your own applications. Anyone else’s applications will at best ignore such an element, or, more likely, reject your document. Not so in DITA land. Even if my application has never heard of your specialised ‘task’, it at least knows about the more general ‘task’, and will happily treat your ‘task’ in those more general terms.
Though DITA is an open OASIS specification, it was developed in IBM as a solution for their pretty vast software documentation needs. They’ve also contributed the useful open source toolkit for processing content into and out of DITA (Sourceforge), with comprehensive documentation, of course.
That toolkit demonstrates the immediate advantage of specialisation: it saves an awful lot of time, because you can re-use as much code as possible. This works both in the input and output stage. For example, a number of transforms already exist in the toolkit to take docbook, html or other input, and transform it into DITA. Tweaking those to accept the html from any random content management system is not very difficult, and once that’s done, all the myriad existing output formats immediately become available. What’s more, any future output formats (e.g. for a new Wiki or VLE format) will be immediately useable once someone, somewhere makes a DITA to new format transform available.
Moreover, later changes and tweaks to your own element specialisations don’t necessarily require re-engineering all tools or transforms. Hence that Darwin moniker. You can evolve datamodels, rather than set them in stone and pray they won’t change.
The catch
All of this means that it quickly becomes more attractive to use DITA than make a set of custom transforms from scratch. But DITA isn’t magic, and there are some catches. One is simply that some assembly is required. Whatever legacy content you have lying around, some tweakery is needed in order to get it into DITA, and out again without losing to much of the original structural meaning.
Also, the spec itself was designed for software documentation. Though several people are taking a long, hard look at specialising it for educational applications (ADL, Edutech Wiki and OASIS itself), that’s not proven yet. Longer, non-screenful types of information have been done, but might not offer enough for those with, say, an existing docbook workflow.
The technology for the toolkit is of a robust, if pedestrian variety. All the elements and specialisations are in Document Type Definitions (DTDs) –a decidly retro XML technology– though you can use the hipper XMLSchema or RelaxNG as well. The toolkit itself is also rather dependent on extensive path hackery. High volume. real time content transformation is therefore probably best done with a new tool set.
Those tool issues are independent of the architecture itself, though. The one tool that would be difficult to remove is XSL Transforms, and that is pretty fundamental. Though ‘proper’ semantic web technology might have offered a far more powerful means to manipulate content meaning in theory, the more limited, but directly implementable XSLTs give it a distinct practical edge.
Finally, direct content authoring and editing in DITA XML poses the same problem that all structural content systems suffer from. Authors want to use MS Office, and couldn’t care less about consistent meaningful document structuring, while the Word format is a bit of a pig to transform and it is very difficult to extract a meaningful structure from something that was randomly styled.
Three types of solution exist for this issue: one is to use a dedicated XML editor meant for the non-angle bracket crowd. Something like XMLMind’s editor is pretty impressive and free to boot, but may only work for dedicated content authors simply because it is not MS Word. You can use MS Word with templates either directly with an plug-in, or with some post-processing via OpenOffice (much like ICE does). Those templates makes Word behave differently from normal, though, which authors may not appreciate.
Perhaps it is, therefore, best to go with the web oriented simplicity, and transform orientation of DITA, and use a Wiki. Wiki formats are so simple that mapping a style to a content structure is pretty safe and robust, and not too alien and complex for most users.