This thought on etextbooks is an overflow from a conversation I was having about a workshop aimed at scoping what we would like the etextbooks of the future to look like. By defining an area of interest as “etextbooks” we were implying a continuity with textbooks, the implication seems to be that etextbooks will pick up where paper text books leave off. That, I think is different from 20 or so years ago when we were talking about how computer based learning marked a step change in how education was delivered. In that case much of the talk was about how technology will radically change education. Even if my characterisation of the two cases as opposing is a bit crude (as it is), it’s worth comparing the two approaches. I’ll do that here, just briefly.
Author Archives: Phil Barker
Heads up for HEDIIP
A while back I summarised the input about semantics and academic coding that Lorna and I had made on behalf of Cetis for a study on possible reforms to JACS, the Joint Academic Coding System. That study has now been published.
JACS is mainatained by HESA (the Higher Education Statistics Agency) and UCAS (Universities and Colleges Admissions Service) as a means of classifying UK University courses by subject; it is also used by a number of other organisations for classification of other resources, for example teaching and learning resources. The report (with appendices) considers the varying requirements and uses of subject coding in HE and sets out options for the development of a replacement for JACS.
Of course, this is all only of glancing interest, until you realise that stuff like Unistats and the Key Information Set (KIS) are powered by JACS.
- See more
ePub metadata what gets shown?
One of the issues around eTextBooks is how to describe them, specifically by way of educational metadata in ePub. That’s something that on the face of it shouldn’t be too difficult to address (at least to the extent that we know how to describe any educational resource). One thing that would be useful in demonstrating different choices for educational metadata is an app or tool that will display any metadata found in the ePub package in a sensible way. As a bit of long shot I tried four eBook readers to see whether they would; they don’t. The details follow, if you’re interested, but do let me know if you know of any tool that might be useful.
The package metadata of an ePub can include a selection of Dublin Core elements and terms. These can be refined, for example you may have two dc:title elements with refinements to specify that one is the main title and the other the subtitle. You can also extend with elements from other XML namespaces, or if you prefer you can just link to a metadata record of your favourite flavour which can be either inside the ePub package or elsewhere on the web. Any of this metadata can relate to the eBook as a whole or some part of it, e.g. a single chapter or image. Without going into details there seems to be enough scope there to experiment with how educational characteristics of the eBook might be described. [..]
Three levels of design and innovation
An electronics company has just won a patent claim against another electronics company. It’s not relevant to this post which companies and what patent were involved, it just served to remind me once again of the different types of innovation that are subject to these patent claims–where there is a patent there is at least a claim of innovation, and that is what interests me. Specifically, I find it interesting that some of these patent claims are for antenna design, others certain user interactions, and that links to an idea I heard presented by Adam Procter a year or so ago which has stuck with me,–that there are three levels to design and innovation:
level one: the base technology. In phones this would be the physical design of antennae, the compression algorithms used for audio and video, the physics of the various sensors, and so on.
level two: the product. That is putting all the base technologies to create features of a working unit that (if it is to be successful) fulfills a need.
level three: user experience. Making the use of those features a pleasure.
I’ve found this useful in thinking about what it is that Apple gets right compared to, say, Nokia. It’s my impression (and I think the various patent claims bear this out) that Apple are very good at innovating for user experience whereas Nokia and others did a lot of the work somewhere around technologies and product.
I’ve also found it enlightening to reflect on just how hard it is to work out from the technology alone what would be a set of features that make up a successful product. I was using CCD cameras for science experiments in the early 90s, when the technology had been around twenty-odd years, and never once did it occur to me that it would be a really good idea to put one in a phone. Light sensors so that your curtains would open and close automatically, sure they were certain to come, but a camera in your phone!–why would anyone want that?
Put those together, and I think what you get is a picture of some people who are good at spotting (or just prepared to experiment with) how technologies can do something useful, and others who are good at spotting what is required in order to make those features pleasant enough to use. So Diamond and Creative and others showed that really small MP3 players were devices that people might find useful (others before them had put together advances in audio compression and storage technology to show such devices were possible), Apple made something that people wanted to use. What was it that made the difference? The integration with iTunes maybe?
Sometimes identifying the useful feature comes before the technology that makes it usable, at least to a certain extent: Palm showed how touch screen devices could be useful but Apple waited until the technology (capacitive rather than resistive sensors) was available to give the user experience they wanted. Of course that area of human endeavour which puts creation of innovative products completely ahead of technology developments is called science fiction–how’s that flying car coming along?
ebooks 2013
Every year for the past dozen or so years the Department of Information Sciences at UCL have organised a meeting on ebooks. I’ve only been to one of them before, two or three years ago, when the big issues were around what publishers’ DRM requirements for ebooks meant for libraries. I came away from that musing on what the web would look like if it had been designed by publishers and librarians (imagine questions like: “when you lend out our web page, how will you know that the person looking at the screen is a member of your library?”…). So I wasn’t sure what to expect when I decided to go to this year’s meeting. It turned out to be far more interesting than I had hoped, I latched on to three themes of particular interest to me: changing paradigms (what is an ebook?), eTextBooks and discovery.
Changing paradigms

With the earliest printed books, or incunabula, such as the Gutenberg Bible, printers sought to mimic the hand written manuscripts with which 15th cent scholars were familiar; in much the same way as publishers now seek to replicate printed books as ebooks.
We need to treat digital content as offering new possibilities and requiring new ways of working. This might be uncomfortable for publishers (some more than others) and there was some discussion about how we cannot assume that all students will naturally see the advantages, especially if they have mostly encountered problematic content that presents little that could not be put on paper but is encumbered with DRM to the point that it is questionable as to whether they really own the book. But there is potential as well as resistance. Of course there can be more interesting, more interactive content–Will Russell of the Royal Society of Chemistry described how they have been publishing to mobile devices, with tools such as Chem Goggles that will recognise a chemical structure and display information about the chemical. More radically, there can also be new business models: Lorraine suggested Institutions could become publishers of their own teaching content, and later in the day Caren Milloy, also of Jisc Collections, and Brian Hole of Ubiquity Press pointed to the possibilities of open access scholarly publishing.
Caren’s work with the OAPEN Library is worth looking through for useful information relating to quality assurance in open monograms such as notifying readers of updates or errata. Caren also talked about the difficulties in advertising that a free online version of a resource is available when much of the dissemination and discovery ecosystem (you know, Amazon, Google…) is geared around selling stuff, difficulties that work with EDitEUR on the ONIX metadata scheme will hopefully address soon.
Brian described how Ubiquity Press can publish open access ebooks by driving down costs and being transparent about what they charge for. They work from XML source, created overseas, from which they can publish in various formats including print on demand, and explore economies of scale by working with university presses, resulting in a charge to the author (or their funders) of about £150 for a chapter assuming there is nothing to complex in that chapter.
eTextBooks
All through the day there were mentions of eTextBooks, starting again with Lorraine who highlighted the paperless medic and how his quest to work only with digital resources is complicated by the non-articulation of the numerous systems he has to use. When she said that what he wanted was all his content (ebooks, lecture handouts, his own notes etc.) on the same platform, integrated with knowledge about when and where he had to be for lectures and when he had exams, I really started to wonder how much functionality can you put into an eContent platform before it really becomes a single-person content-oriented VLE. And when you add in the ability to share notes with the social and communication capability of most mobile devices, what then do you have?
A couple of presentations addressed eTextBooks directly, from a commercial point of view. Jenni Evans spoke about Vital Source and Andrejs Alferovs about Kortext both of which are in the business of working with institutions distributing online textbooks to students. Both seem to have a good grasp of what students want, which I think should be useful requirements to feed into eTextBook standardization efforts such as eTernity, these include:
- ability to print
- offline access
- availability across multiple devices
- reliable access under load
- integration with VLE
- integration with syllabus/curriculum
- epub3 interactive content
- long term access
- ability for student to highlight/annotate text and share this with chosen friends
- ability to search text and annotations
Discovery
There was also a theme of resource discovery running through the day, and I have already mentioned in passing that this referenced Google and Amazon, but also social media. Nick Canty spoke about a survey of library use of social media, I thought it interesting that there seemed to be some sophisticated use of the immediacy of Twitter to direct people to more permanent content, e.g. to engagement on Facebook or the library website.
Both Richard Wallis of OCLC and Robert Faber of OUP emphasized that users tend to use Google to search and gave figures for how much of the access to library catalogue pages came direct from Google and other external systems, not from their own catalogue search interface. For example the Biblioteque Nationale de France found that 80% of access to their catalogue pages cam directly from web search engines not catalogue searches, and Robert gave similar figures for access to Oxford Journals. The immediate consequence of this is that if most people are trying to find content using external systems then you need to make sure that at least some (as much as possible, in fact) of your content is visible to them–this feeds in to arguments about how open access helps solve discoverability problems. But Richard went further, he spoke about how the metadata describing the resources needs to be in a language that Google/Bing/Yahoo understand, and that language is schema.org. He did a very good job distinguishing between the usefulness of specialist metadata schema for exchanging precise information between libraries or publishers, but when trying to pass general information to Google:
it’s no use using a language only you speak.
Richard went on to speak about the Google Knowledge graph and their “things not strings” approach facilitated by linked data. He urged libraries to stop copying text and to start linking, for example not to copy an author name from an authority file but to link to the entry in that file, in Eric Miller’s words to move from cataloguing to “catalinking”.
ebooks?
So was this really about ebooks? Probably not, and the point was made that over the years the name of the event has variously stressed ebooks and econtent and that over that time what is meant by “ebook” has changed. I must admit that for me there is something about the idea of a [e]book that I prefer over a “content aggregation” but if we use the term ebook, let’s use it acknowledging that the book of the future will be as different from what we have now as what we have now is from the medieval scroll.
Picture Credit
Scanned image of page of the Epistle of St Jerome in the Gutenberg bible taken from Wikipedia. No Copyright.
Learning Resource Metadata is Go for Schema
The Learning Resource Metadata Initiative aimed to help people discover useful learning resources by adding to the schema.org ontology properties to describe educational characteristics of creative works. Well, as of the release of schema draft version 1.0a a couple of weeks ago, the LRMI properties are in the official schema.org ontology.
Schema.org represents two things: 1, an ontology for describing resources on the web, with a hierarchical set of resource types each with defined properties that relate to their characteristics and relationships with other things in the schema hierarchy; and 2, a syntax for embedding these into HTML pages–well, two syntaxes, microdata and RDFa lite. The important factor in schema.org is that it is backed by Google, Yahoo, Bing and Yandex, which should be useful for resource discovery. The inclusion of the LRMI properties means that you can now use schema.org to mark up your descriptions of the following characteristics of a creative work:
audience the educational audience for whom the resource was created, who might have educational roles such as teacher, learner, parent.
educational alignment an alignment to an established educational framework, for example a curriculum or frameworks of educational levels or competencies. Expressed through an abstract thing called an Alignment Object which allows a link to and description of the node in the framework to which the resource aligns, and specifies the nature of the alignment, which might be that the resource ‘assesses’, ‘teaches’ or ‘requires’ the knowledge/skills/competency to which the resource aligns or that it has the ‘textComplexity’, ‘readingLevel’, ‘educationalSubject’ or ‘educationLevel’ expressed by that node in the educational framework.
educational use a text description of purpose of the resource in education, for example assignment, group work.
interactivity type The predominant mode of learning supported by the learning resource. Acceptable values are ‘active’, ‘expositive’, or ‘mixed’.
is based on url A resource that was used in the creation of this resource. Useful for when a learning resource is a derivative of some other resource.
learning resource type The predominant type or kind characterizing the learning resource. For example, ‘presentation’, ‘handout’.
time required Approximate or typical time it takes to work with or through this learning resource for the typical intended target audience
typical age range The typical range of ages the content’s intended end user.
Of course, much of the other information one would want to provide about a learning resource (what it is about, who wrote it, who published it, when it was written/published, where it is available, what it costs) was already in schema.org.
Unfortunately one really important property suggested by LRMI hasn’t yet made the cut, that is useRightsURL, a link to the licence under which the resource may be used, for example the creative common licence under which is has been released. This was held back because of obvious overlaps with non-educational resources. The managers of schema.org want to make sure that there is a single solution that works across all domains.
Guides and tools
To promote the uptake of these properties, the Association of Educational Publishers has released two new user guides.
The Smart Publisher’s Guide to LRMI Tagging (pdf)
The Content Developer’s Guide to the LRMI and Learning Registry (pdf)
There is also the InBloom Tagger described and demonstrated in this video.
LRMI in the Learning Registry
As the last two resources show, LRMI metadata is used by the Learning Registry and services built on it. For what it is worth, I am not sure that is a great example of its potential. For me the strong point of LRMI/schema.org is that it allows resource descriptions in human readable web pages to be interpreted as machine readable metadata, helping create services to find those pages; crucially the metadata is embedded in the web page in way that Google trusts because the values of the metadata are displayed to users. Take away the embedding in human readable pages, which is what seems to happen when used with the learning registry, and I am not sure there is much of an advantage for LRMI compared to other metadata schema,–though to be fair I’m not sure that there is any comparative disadvantage either, and the effect on uptake will be positive for both sides. Of course the Learning Registry is metadata agnostic, so having LRMI/schema.org metadata in there won’t get in the way of using other metadata schema.
Disclosure (or bragging)
I was lucky enough to be on the LRMI technical working group that helped make this happen. It makes me vary happy to see this progress.
On Semantics and the Joint Academic Coding System
Lorna and I recently contributed a study on possible reforms to JACS, a study which is part of a larger piece of work on Redesigning the HE data landscape. JACS, the Joint Academic Coding System, is mainatained by HESA (the Higher Education Statistics Agency) and UCAS (Universities and Colleges Admissions Service) as a means of classifying UK University courses by subject; it is also used by a number of other organisations for classification of other resources, for example teaching and learning resources. The study to which we were contributing our thoughts had already identified a problem with different people using JACS in different ways, which prompted the first part of this post. We were keen to promote technical changes to the way that JACS is managed that would make it easier for other people to use (and incidentally might help solve some of the problems in further developing JACS for use by HESA and UCAS), which are outline in the second part.
There’s nothing new here, I’m posting these thoughts here just so that they don’t get completely lost.
Subjects and disciplines in JACS
One of the issue identified with the use of JACS is that “although ostensibly believing themselves to be using a single system of classification, stakeholders are actually applying JACS for a variety of different purposes” including Universities who “often try to align JACS codes to their cost centres rather than adopting a strictly subject-based approach”. The cost centres in question are academic schools or departments, which are discipline based. This is problematic to the use of JACS to monitor which subjects are being learnt since the same subject may be taught in several departments. A good example of this is statistics, which is taught across many fields from Mathematics through to social sciences, but there are many other examples: languages taught in mediaeval studies and business translation courses, elements of computing taught in electronic engineering and computer science and so on. One approach would be to ignore the discipline dimension, to say the subject is the same regardless of the different disciplinary slants taken, that is to say statistics taught to mathematicians is the same as statistics taught to physicists is the same as statistics taught to social sciences. This may be true at a very superficial level, but obviously the relevance of theoretical versus practical elements will vary between those disciplines, as will the nature of the data to be analysed (typically a physicist will design an experiment to control each variable independently so as not to deal with multivariate data, this is not often possible in social sciences and so multivariate analysis is far more important). When it comes to teaching and learning resources something aimed at one discipline is likely to contain examples or use an approach not suited to others.
Perhaps more important is that academics identify with a discipline as being more than a collection of subjects being taught. It encapsulates a way of thinking, a framework for deciding on which problems are worth studying and a way of approaching these problems. A discipline is a community, and an academic who has grown up in a community will likely have acquired that community’s view of the subjects important to it. This should be taken into account when designing a coding scheme that is to be used by academics since any perception that the topic they teach is being placed under someone else’s discipline will be resisted as misrepresenting what is actually being taught, indeed as a threat to the integrity of the discipline.
More objectively, the case for different disciplinary slants on a problem space being important is demonstrated by the importance of multidisciplinary approaches to solving many problems. Both the reductionist approach of physics and the holistic approach of humanities and social sciences have their strengths, and it would be a shame if the distinction were lost.
The ideal coding scheme would be able to represent both the subject learnt and the discipline context in which it was learnt.
JACS and 5* data
Tim Berners-Lee suggested a 5 star deployment scheme for open data on the world wide web:
* make your stuff available on the Web (whatever format) under an open licence
** make it available as structured data (e.g., Excel instead of image scan of a table)
*** use non-proprietary formats (e.g., CSV instead of Excel)
**** use URIs to denote things, so that people can point at your stuff
**** link your data to other data to provide context
Currently JACS fails to meet the open licence requirement for 1-star data explicitly, but that seems to be a simple omission of a licensing statement that shows the intention that JACS should be freely available for others to use. It is important that this is fixed, but aside from this, JACS operates at about 3-star level. Assigning URIs to JACS subjects and providing useful information when someone accesses these URIs will allow JACS to be part of the web of linked open data. The benefits of linking data over the web include:
- The identifiers are globally unique and unambiguous, they can be used in any system without fear of conflicting with other identifiers.
- The subjects can be referenced globally by humans by from websites, emails, and by computer systems in/from data feeds and web applications.
- The subjects can be used for semantic web approaches to representing ontologies, such as RDF.
- These allow relationships such as subject hierarchies and relationships with other concepts (e.g. academic discipline) to be represented independently of the coding scheme used. An example of this is SKOS, see below.
In practical terms, implementing this would mean:
- Devising a URI scheme. This could be as simple as adding the JACS codes to a suitable base URI. For example H713 could become http://id.jacs.ac.uk/H713
- Setting up a web service to provide suitable information. Anyone connecting to that URL would be redirected to information that matched parameters in their request. A simple web browser would request an HTML page and so be redirected to http://id.jacs.ac.uk/H713.html; web applications would request data in a machine readable form such as xml, rdf or json.
The main overhead is in setting up, maintaining and managing the data provided by the web service, but Southampton University have already set one up for their own use. (The only problem with the Southampton service–and I believe Oxford have done something similar–is a lack of authority, i.e. it isn’t clear to other users whether the data from this service is authoritative, up to date, used under a correct license, sustainable.)
JACS and SKOS
SKOS (Simple Knowledge Organization System) is a semantic web application of RDF which provides a model for expressing the basic structure and content of concept schemes such as thesauri, classification schemes, subject heading lists, taxonomies, folksonomies, and other similar types of controlled vocabulary. It allows for the description of a concept and the expression of the relationship betweens pairs of concepts. But first the concept must be identified as such, with a URI. For example:
jacs:H713 rdf:type skos:concept
In this example jacs: is shorthand for the JACS base URI, http://id.jacs.ac.uk/ as suggested above; rdf: and skos: are shorthand for the base URIs for RDF and SKOS. This triple says “The thing identified by http://id.jacs.ac.uk/H713 is a resource of type (as defined by RDF) concept (as defined by SKOS)”.
Other assertions can be made about the resource, e.g. the preferred label to be used for it and a scope note for it.
jacs:H713 skos:prefLabel “Production Processes”
jacs:H713 skos:scopeNote “The study of the principles of engineering as they apply to efficient application of production-line technology.”
Assuming the other JACS codes have been suitably identified, relationships between them can be described:
jacs:H713 skos:broader jacs:H710
jacs:H713 skos:related jacs:H830
Once JACS is on the semantic web relationships between the JACS subjects and things in other schemas can also be represented
http://example.org/123 dct:subject jacs:H713
(The resource identified by the URI http://example.org/123 is about the subject identified by jacs:H713).
Book now available. Into the Wild – Technology for Open Educational Resources

Into the Wild (Book cover)
From the blurb:
Between 2009 and 2012 the Higher Education Funding Council funded a series of programmes to encourage higher education institutions in the UK to release existing educational content as Open Educational Resources. The HEFCE-funded UK OER Programme was run and managed by the JISC and the Higher Education Academy. The JISC CETIS “OER Technology Support Project” provided support for technical innovation across this programme. This book synthesises and reflects on the approaches taken and lessons learnt across the Programme and by the Support Project.
This book is not intended as a beginners guide or a technical manual, instead it is an expert synthesis of the key technical issues arising from a national publicly-funded programme. It is intended for people working with technology to support the creation, management, dissemination and tracking of open educational resources, and particularly those who design digital infrastructure and services at institutional and national level.
You may remember Lorna writing back in August that Amber Thomas, Martin Hawksey, Lorna and I had written 90% of this book together in a Book Sprint. Well, the last 10% and the publication turned in to a bit of a marathon-relay, something about which I might write some time, but now the book is available in a variety of formats:
- If you want glossy-covered paperback, then you can order it print-on-demand from Lulu (£3.36); if you’re not so fussed about the glossy cover and binding then there is a print-quality pdf you can print yourself.
- If you have an ePub reader you can download, there is a free download of an epub2 file.
- If you have a Kindle, you can download the .mobi file and transfer it, or if you prefer the convenience of Amazon’s distribution over whisper-net you can buy it from them (77p, they don’t seem to distribute for free unless you agree to give them exclusive rights for all electronic formats).
- finally, if you prefer your ebook reading as PDFs, there is one of those too.
All varieties are free or at minimum cost for the distribution channel used; the content is cc-by licensed and editable versions are available if you wish to remix and fix what we’ve done.
Brief reflections on Open Practice and OER Sustainability
Lorna and I ran a session at the CETIS conference on the topic of Open Practice and OER Sustainability, we had 10-minute presentations from ten brilliant people who have been involved in the UKOER programme each giving a view from their own perspective on the general problem of “what now that the Jisc money has gone?” It’s fruitless to try to summarise that in full, so what I will do is add links to presentations to the session page linked-to above and give my own very cursory summary of a few of the themes. Lorna has also written a summary on her own blog.
“Scratch your own itch”
One of the most telling comments on sustainability, from Julian Tenney talking about the Xerte project, was that a project would most likely be sustainable if it was about doing something that the people involved needed doing anyway. Not necessarily something that would be done anyway (though in Xerte’s case mostly it was), but definitely not something that was being done just because the money was there. I agree with a comment that was made that there is a problem with the way that Universities treat project funding in this respect (at least in research departments), always the emphasis is on chasing money, getting the next grant. There were many examples of what it might be that “needs doing anyway”, at personal, subject community, institutional, and national/sector-wide level, from the sharing of resources between humanities teachers using HumBox, extra mural studies of the Department of continuing Education at Oxford University, the institutional teaching and learning policy at Leeds Met University, FE colleges in Scotland working in ever closer union and student progression from College to University.
 (By: Nick Sheppard, Leeds Metropolitan University)
(By: Nick Sheppard, Leeds Metropolitan University)
Nick Sheppard asked for a technical infrastructure to support these institutional and other policies. He (and others) asked for APIs and other links between repositories (and the rest of the web, I assume) so that the greatest advantage could be had for effort. Sarah Currier told us about the new offers from Mimas to make your OER effort “Jorum Powered” through a hosted repository, a web interface into Jorum, or by building custom applications using the new Jorum API.
But with technical infrastructure come technical requirements, David Kernohan was worried that these requirements are only bearable by an academic with help, and that once the Jisc funding goes that support will also go. Suzanne Hardy also touched on this.
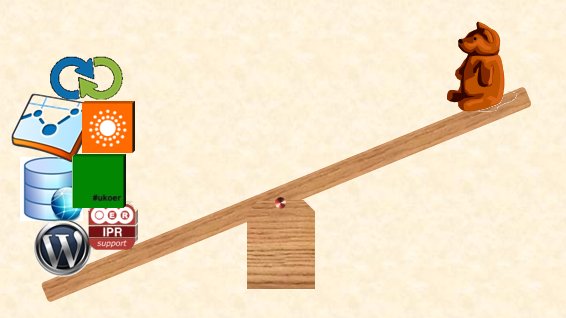
by David Kernohan, Jisc. The teddy bear is an academic.
The concept involved here was identified by Yvonne Howard as relative advantage, the advantage of something has to be compared to the costs and the costs have to be minimised, as can be done through clever technology such as maximum use of machine created metadata.
“It’s like MOOCs stole OER’s girlfriend”
 So far I’ve mentioned advantages for many people but glossed over the fact that different people will see different advantages; they don’t and for that reason they will pursue different directions, as we have seen with MOOCs. Amber Thomas of Warwick University (but yes, the same Amber as was of JISC) described MOOCs and OERs as distant cousins who used to get on but are now no longer friendly for some reason. And it’s not like the O for Open in the two really stands for the same thing, as Pat Lockley said, their open is not necessarily our open. But, he asked, what is open? a footpath through private land or a National Park with the right to roam where you please (if you can manage to get there)?
So far I’ve mentioned advantages for many people but glossed over the fact that different people will see different advantages; they don’t and for that reason they will pursue different directions, as we have seen with MOOCs. Amber Thomas of Warwick University (but yes, the same Amber as was of JISC) described MOOCs and OERs as distant cousins who used to get on but are now no longer friendly for some reason. And it’s not like the O for Open in the two really stands for the same thing, as Pat Lockley said, their open is not necessarily our open. But, he asked, what is open? a footpath through private land or a National Park with the right to roam where you please (if you can manage to get there)?
(this last photo is mine and is covered by the CC-BY licence of this blog; the others aren’t and are used according to their various licences or permissions from their creators.)
eTextBooks Europe
I went to a meeting for stakeholders interested in the eTernity (European textbook reusability networking and interoperability) initiative. The hope is that eTernity will be a project of the CEN Workshop on Learning Technologies with the objective of gathering requirements and proposing a framework to provide European input to ongoing work by ISO/IEC JTC 1/SC36, WG6 & WG4 on eTextBooks (which is currently based around Chinese and Korean specifications). Incidentally, as part of the ISO work there is a questionnaire asking for information that will be used to help decide what that standard should include. I would encourage anyone interested to fill it in.
The stakeholders present represented many perspectives from throughout Europe: publishers, publishing industry specification bodies (e.g. IPDF who own EPUB3, and DAISY), national bodies with some sort of remit for educational technology, and elearning specification and standardisation organisations. I gave a short presentation on the OER perspective.
Many issues were raised through the course of the day, including (in no particular order)
- Interactive and multimedia content in eTextbooks
- Accessibility of eTextbooks
- eTextbooks shouldn’t be monolithic and immutable chunks of content, it should be possible to link directly to specific locations or to disaggregate the content
- The lifecycle of an eTextbook. This goes beyond initial authoring and publishing
- Quality assurance (of content and pedagogic approach)
- Alignment with specific curricula
- Personalization and adaptation to individual needs and requirements
- The ability to describe the learning pathway embodied in an eTextbook, and vary either the content used on this pathway or to provide different pathways through the same content
- The ability to describe a range IPR and licensing arrangements of the whole and of specific components of the eTextbook
- The ability to interact with learning systems with data flowing in both directions
If you’re thinking that sounds like a list of the educational technology issues that we have been busy with for the last decade or two, then I would agree with you. Furthermore, there is a decade or two’s worth of educational technology specs and standards that address these issues. Of course not all of those specs and standards are necessarily the right ones for now, and there are others that have more traction within digital publishing. EPUB3 was well represented in the meeting (DITA is the other publishing standard mentioned in the eTernity documentation, but no one was at the meeting to talk about that) and it doesn’t seem impossible to meet the educational requirements outlined in the meeting within the general EPUB3 framework. The question is which issues should be prioritised and how should they be addressed.
Of course a technical standard is only an enabler: it doesn’t in itself make any change to teaching and learning; change will only happen if developers create tools and authors create resources that exploit the standard. For various reasons that hasn’t happened with some of the existing specs and standards. A technical standard can facilitate change but there needs to a will or a necessity to change in the first place. One thing that made me hopeful about this was a point made by Owen White of Pearson that he did not to think of the business he is in as being centred around content creation and publishing but around education and learning and that leads away from the view of eBooks as isolated static aggregations.
For more information keep an eye on the eTernity website