Last week at the University of Bolton we put on a workshop for final year students that were about to embark on a job hunt. While the workshop was held in conjunction with the careers advice service and there was chance to give students a hand with practical things such as CV writing and interview technique we also wanted to get the students to talk to one another, reflect and share experiences from their time at the University to boost their confidence and help each other identify things such as transferable skills and job hunting tips.

Graph Widget example and the lone psychology job hunter (click to enlarge)
Before the event I built some bits of software with the aim to provide Sheila and Stephens first possibility of Learning Analytics. That is the possibility that learning analytics could allow ‘individual learners to reflect on their achievements and patterns of behaviour in relation to others’. The software was quite simple, there were two sets of widgets, one set of widgets was designed to collect information from the students. This set of widgets was mode up simple text forms of checkboxes that the students could access on their laptops/phones/ipads. Questions where asked in a variety of ways, sometimes the widget itself would prompt the student with a question and waited for an answer (what the questions were and when they where asked were controlled by staff) and sometimes they were simply asked to input answers/thoughts/feelings during various stages of an activity (involving an activity with play doh!).

Example Tree Widget, at this stage most students claimed they weren't on the job hunt.. (Click to enlarge)
The other set was designed to show the students how their experiences related to those of other students by a series of d3.js powered visualisations. Each of these widgets had a single visualisation on and a collection if them where shown on a dashboard at the front of the workshop hall and were updated in real time, so that if a student added a response to an input widget they could instantly see how it fit in to the big picture. Students also had the ability to take away single visualisations and interact with them on their own devices.

If I said X am I likely to say Y
We had approached the event with quite a ‘handwavy’ idea, we weren’t sure if the visualisations or data would mean anything to the students, my colleague was writing bits of code 5 minutes before the event and at one point I had to add some data sanitization during one of the exercises, to keep the widgets alive. Still, the students seemed to really like real time feedback from the analytics. Students regularly checked the dashboard waiting for their answers to pop up on the screen to see who gave similar answers and where their answers sat in the grand scheme of things. Most importantly it got them talking to each other, the input widgets gave them the ability to go back and change answers and there were some tactical changes between groups of students to improve what their future picture looked like.
My todo list:
- Fix Widgets, get a working demo!
- Work on ways to share the activity (via OMDL)
- Try to capture more data next time
The widgets are in a sorry state with lots of bubblegum code and hacks sticking bits together. Better sort them out and get a working demo up!
Lots of students (particularly psychology students!) liked the real time dashboard of answers and wondered if they could implement it themselves for their own events. This isn’t a problem if the widgets are to go in Moodle or Apache Rave then this wouldn’t be a problem since we can use ODML, essentially a MarkUp language that defines widgets and their layout so they can be moved from one platform to another.
Feeding the data back to the students was interesting but I wonder what we can learn about our event from it? Something I didn’t collect but would be interested in was the points of the event where the students decided to change their data. I wonder what it was that made them change their answer from ‘not currently looking for a job’ to ‘desperately applying for everything’.

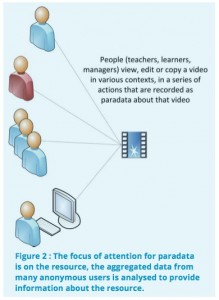 While Activity Streams record the actions of individual users and their interactions with multiple resources and services, other specifications have been developed to record the actions of multiple users on individual resources. This data about how and in what context resources are used is often referred to as Paradata. Paradata complements formal metadata by providing an additional layer of contextual information about how resources are being used. A specification for recording and exchanging paradata has been developed by the Learning Registry, an open source content-distribution network for storing and sharing information about learning resources.
While Activity Streams record the actions of individual users and their interactions with multiple resources and services, other specifications have been developed to record the actions of multiple users on individual resources. This data about how and in what context resources are used is often referred to as Paradata. Paradata complements formal metadata by providing an additional layer of contextual information about how resources are being used. A specification for recording and exchanging paradata has been developed by the Learning Registry, an open source content-distribution network for storing and sharing information about learning resources.


