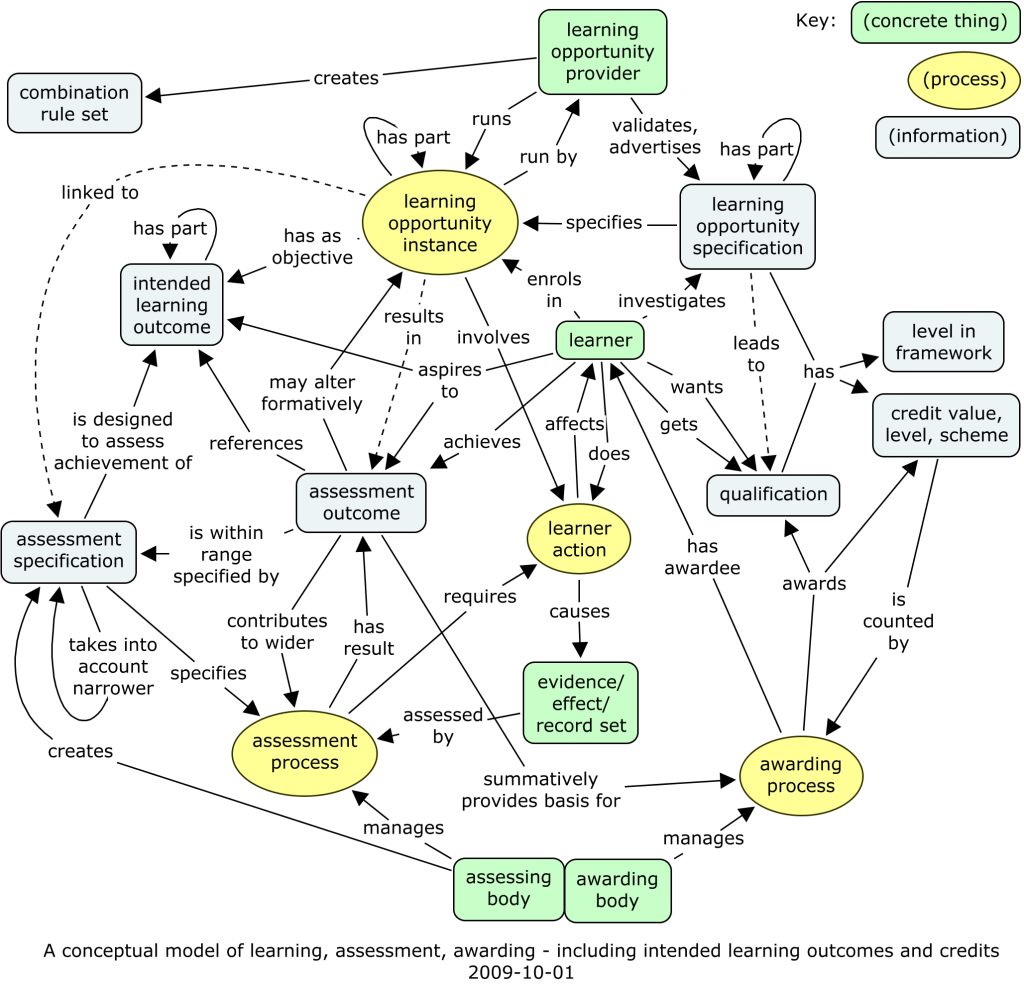
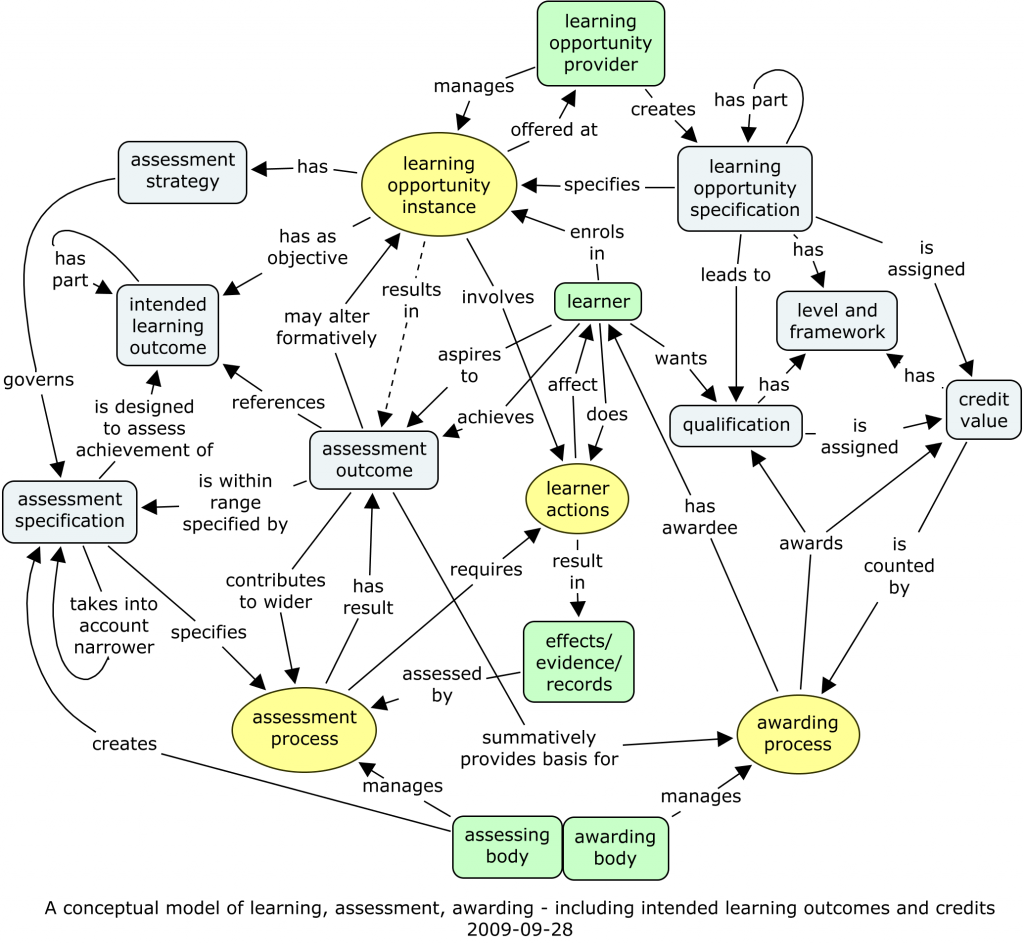
The CEN WS-LT Competency SIG discussions of a conceptual model for skill/competence/competency are still at the very interesting early stage where very many questions are open. What kind of model are we trying to reach, and how can we get to where we could get? Anything seems possible, including experiments with procedures and conventions to help towards consensus.
Tuesday, December 1st, Berlin — a rainy day in the Ambassador Hotel, talking with an esteemed bunch of people about modelling skill/competence/competency. I won’t go on about participants and agenda — these can be seen at http://sites.google.com/site/competencydriven/ It was all interesting stuff, conducted in a positive atmosphere of enquiry. I’ll write here about just the issues that struck me, which were quite enough…
How many kinds of model are there?
At the meeting, there seemed to be quite some uncertainty about what kind of model we might be trying to agree on. I don’t know about other people, but I discern two kinds of model:
- a conceptual model attempting to represent how people understand entities and relationships in the world;
- an information model that could be used for expressing and exchanging information of common interest.
A binding isn’t really a separate model, but an expression of an information model.
My position, which I know is shared by several others, is that to be effective, information models should be based on common conceptual models. The point here is that without an agreed conceptual model, it is all too easy to imagine that you are building an information model where the terms mean the same thing, and play the same role. This could lead to conflict when agreeing the information model, as different people’s ideas would be based on different conceptual models, which would be hard to reconcile, or even worse in the long term, troublesome ambiguity could become embedded in an information model. Not all ambiguity is troublesome, if the things you are being ambiguous about really share the same information model, but no doubt you can imagine what I mean.
Claims and requirements for competence
A long-term aim of many people is to match what is learned in education with what is required for employment — Luk Vervenne was as usual championing the employer point of view. After reflection on what we have at the moment, and incorporating some of Luk’s ideas in the common information model I’ve been putting together, I’d say we have enough there to make a start, at least, in detailing what a competency claim might be, and how that might relate to a competency requirement.
In outline, a full claim for a single separate competence component could have
- the definition of that component (or just a title or brief description if no proper definition available)
- any assessment relevant to that component, with result
- any qualification or other status relevant to that component (which may imply assessment result)
- a narrative filling the gap between qualifications or assessment and what is claimed
- any relevant testimonials
- a record of relevant experience requiring, or likely to lead to, that competence component
- links to / location of any other relevant “raw” (i.e. unassessed) evidence
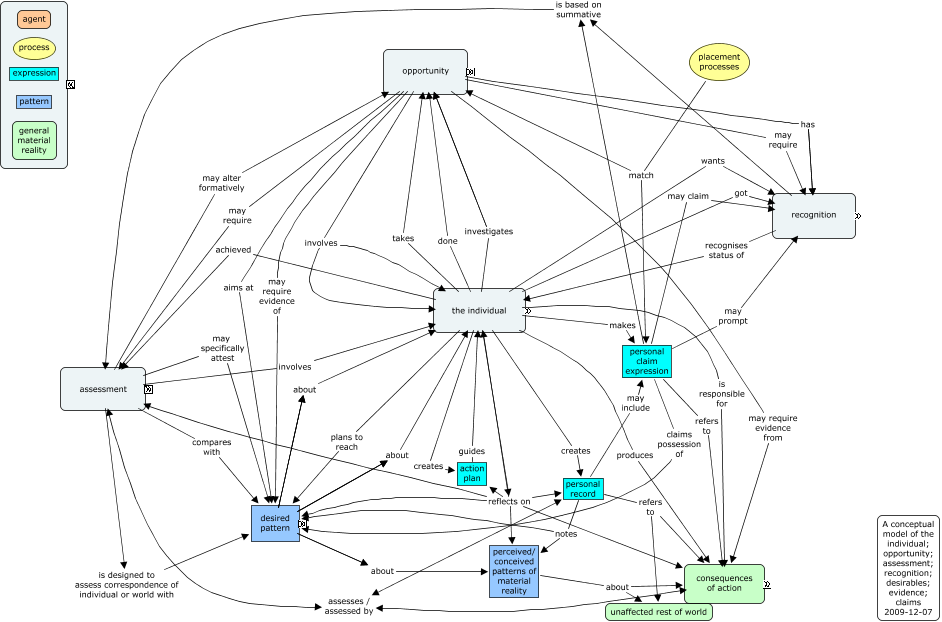
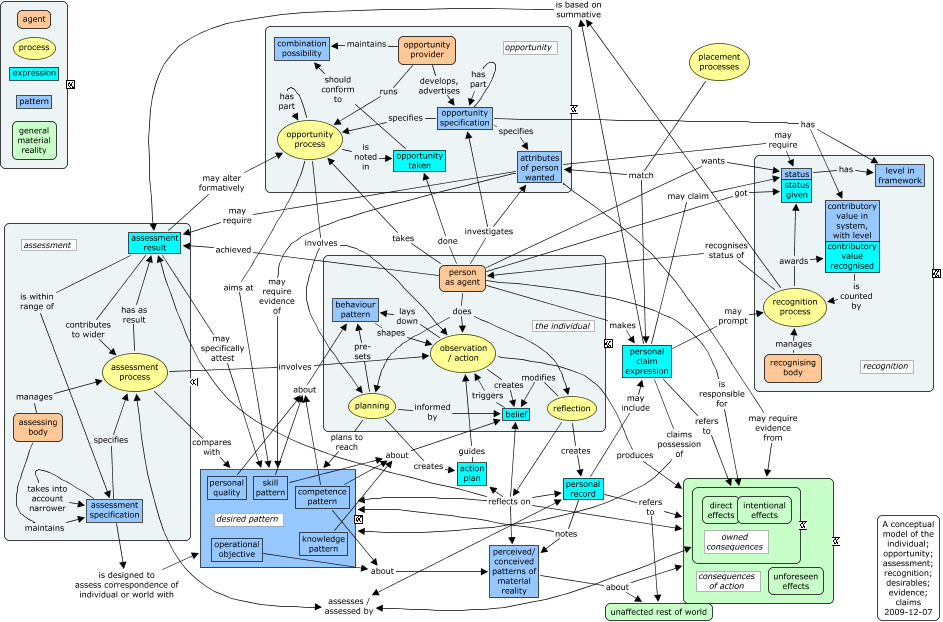
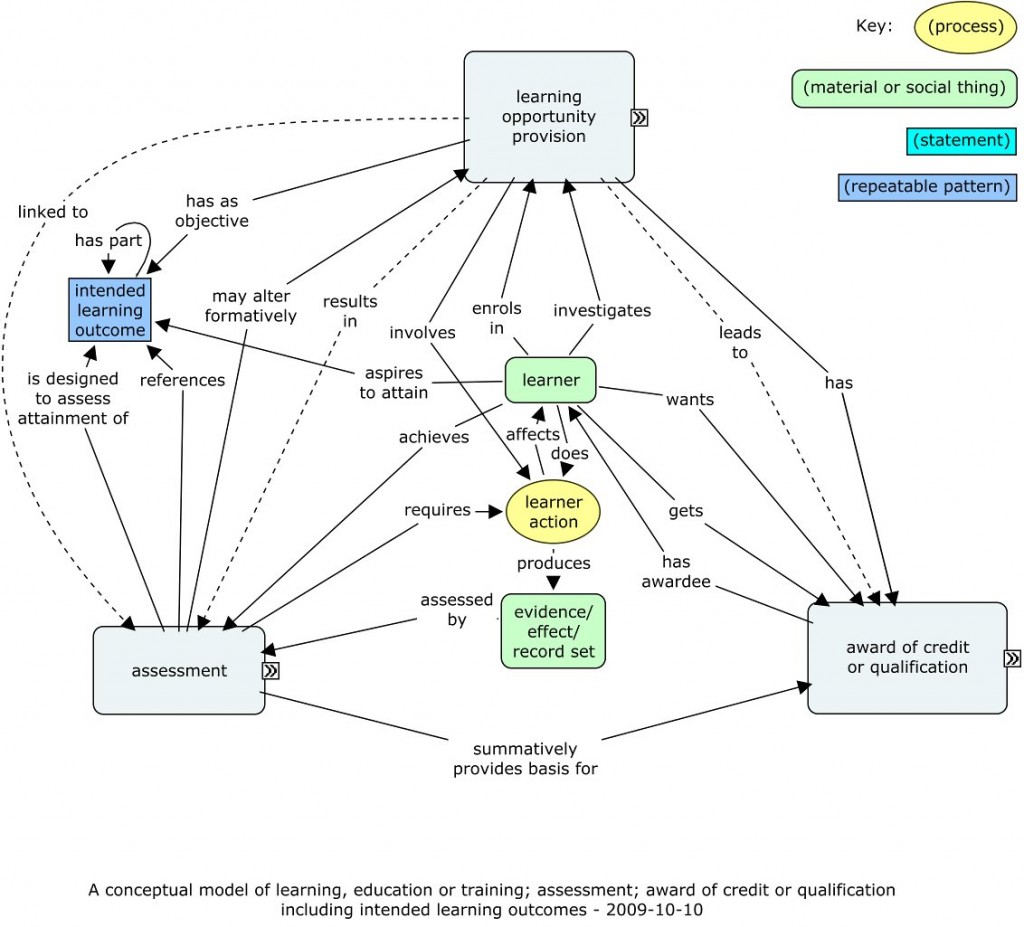
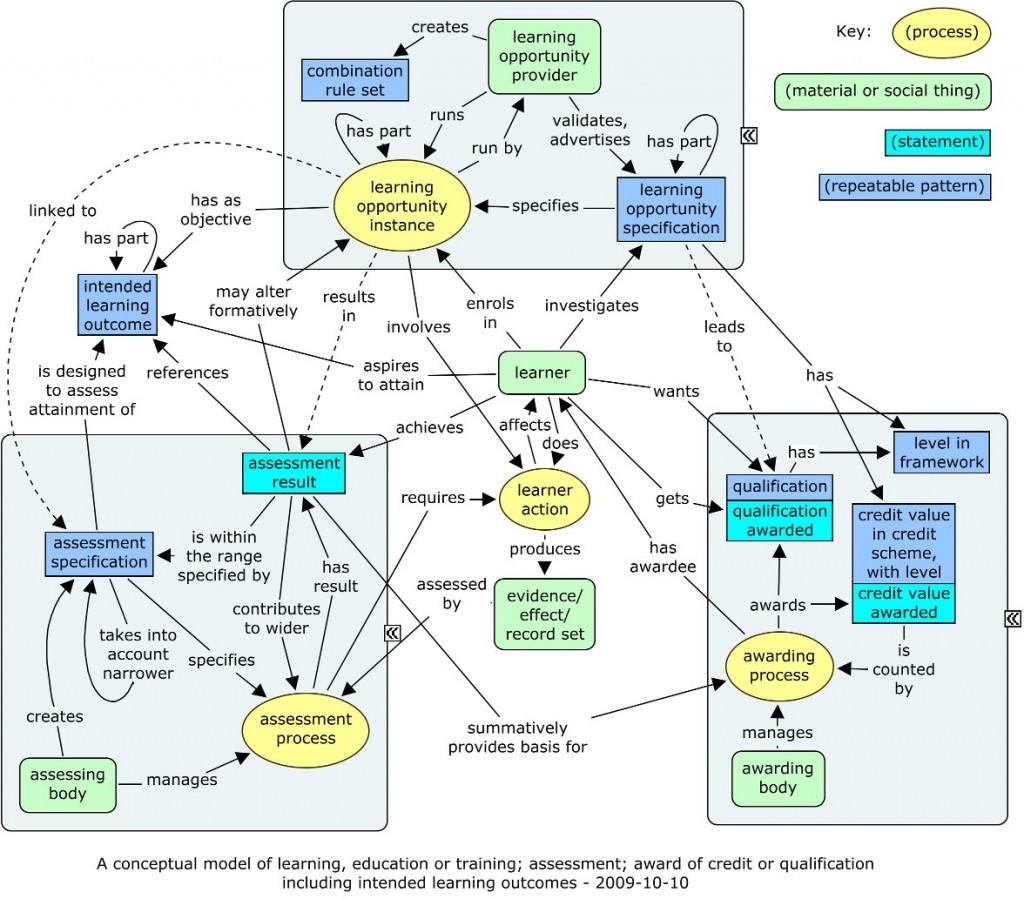
I’ll detail later a possible model of competency requirements, and detail how the two could fit together. And I have now put up the latest version of the big conceptual model as well. There is clearly also a consequent need to be clearer about the structure of assessments, and we’ll be working on that, probably both within CETIS and within the CEN WS-LT.
What about competencies in themselves?
Reflected in the meeting, there still seems to be plenty of disagreement about the detail that is possible in an information model of a competency. Lester Gilbert, for example put forward a model in which he distinguished, for a fully specified educational objective:
- situation;
- constraints;
- learned capability;
- subject matter content;
- standard of performance;
- tools.
The question here, surely, is, to what extent are these facets of a definition (a) common and shared (b) amenable to representation in a usefully machine-processable way?
Personally, I wouldn’t like to rule anything in or out before investigating more fully. At least this could be a systematic investigation, looking at current practice across a range of application areas, carefully comparing what is used in the different areas. I have little difficulty believing that for most if not all learning outcomes or competency definitions, you could write a piece of text to fit into each of Lester’s headings. What I am much more doubtful about is whether there is any scheme that would get us beyond human-readable text into the situation where we could do any automatic matching on these values. Even if there are potential solutions for some, like medical subject headings for the subject matter content, we would need these labels to be pretty repeatable and consistent in order for them to be used automatically. And, what would we do with things like “situation”? The very best I could imagine for situation would be a classification of the different situations that are encountered in the course of a particular occupation. In UK NOSs, these might be written in to the documentation, either explicitly or implicitly. Similar considerations would apply to Lester’s “tools” facet. This might be tractable in the longer term, but would require at least the creation of many domain-specific ontologies, and the linking of any particular definition to one of these domain ontologies.
I can also envisage, as I have been advocating for some time, that some competency definitions would have ontology-like links to other related definitions. These could be ones of equivalence, or the SKOS terms “broadMatch” and “narrowMatch”, in cases where the authorities maintaining the definitions believed that in all contexts, the relationship was applicable.
What about frameworks of skill, competence, etc.?
It surprised me a little that we didn’t actually get round to talking about this in Berlin. But on reflection, with so many other fundamental questions still on the table, perhaps it was only to be expected. Interestingly, so far, I have found more progress here in my participation with MedBiquitous than with the CEN WS-LT.
I’ll write more about this later, but just to trail the key ideas in my version of the MedBiquitous approach:
- a framework has some metadata (DC is a good basis), a set of competency objects, and a map;
- the map is a set of propositions about the individual competency objects, relating them to each other and to objects that are not part of the framework;
- frameworks themselves can be linked to as constituent parts of a framework, just as individual competency objects;
- it is specified whether to accept the relationships defined within the competency objects, and in particular any breakdown into parts.
The point here is that just about any competency definition could, in principle, be analysed into a set of lower-level skills or competencies. This would be a framework. Equally, most frameworks could be used as objectives in themselves, so playing the same role as an individual competency object, being part of a competency framework. If a framework is included, and marked for including its constituent parts, then all those constituent parts would become part of the framework, by inclusion rather than by direct naming. In this way, it would be easy to extend someone else’s framework rather than duplicating it all.
Need for innovations in process and convention
Perhaps the most interesting conclusion from my point of view was about how we could conduct the processes better. There is a temptation to see the process as a competition between models — this would assume that each model is fixed in advance, and that people can be objective about their own, as well as other people’s models. Probably neither of these assumptions is justified. Most people seem to accept the question as “how can a common conceptual model be made from these models?”, even though there may be little wisdom around on how to do this. There is also the half-way approach of “what common information elements can be discerned between these models?” that might come into play if the greater aim of unifying the conceptual models was relinquished.
From my point of view, this brings me back to two points that I have come to recognise only in recent months.
This meeting, for me, displayed some of the same pattern as many previous ones. I was interested in the models being put forward Luk, and Lester, and others, but it was all too easy not to fully understand them, not quite to reach the stage of recognising the insights from them that could be applied to the model I’m continuing to put together. I put this down to the fact that the meeting environment is not conducive to a deep mutual understanding. One can ask a question here and there, but the questions of others may be related more to their own models, not to the relationship of the model under discussion with one’s own. So, one gets the feeling at the end of the meeting that one hasn’t fully grasped the direction one should take one’s own model. Little growth and development results.
So I proposed in the meeting what I have not actually proposed in a meeting before, that we schedule as many one-to-one conceptual encounters as are needed to facilitate that mutual growth of models at least towards the mutual understanding that could allow a meaningful composite to be assembled, if not a fully constituted isomorphism. I don’t know if people will be bold enough to do this, but I’ll keep on suggesting it in different forums until someone does, because I want to know if it is really an effective strategy.
The other point that struck me again was about the highest-level ontology used. One of the criteria, to my mind, of a conceptual model being truly shared, is that people answer questions about the concepts in recognisably similar ways, or largely the same on a multiple choice basis. Some of those questions could easily relate to the essential nature of the concept in question. In the terms of my own top ontology, is the concept about the material world? Or is it a repeatable pattern, belonging to the world of perception and thought? Is it, rather a concept related to communication — an expression of some kind? Whether this is exactly the most helpful set of distinctions is not the main point — it is that some set of distinctions like this will surely help people to clarify what kind of concepts they are discussing and representing in a conceptual model, and thus help people towards that mutual understanding.
A similar, but less clear point seems to apply to relationships between concepts. Allowed free rein in writing a conceptual model, people seem to write all kinds of things in for the relationships between concepts. Some of them seems to tie things in knots — “is a model of” for instance. So maybe, as well as having clear types for concepts, maybe we could agree a limited vocabulary for permitted relationships. That would certainly help the process of mapping two concept maps to each other. There are also two related conventions I have used in my most recent conceptual model.
- Whole-part relationships are represented by having contained concepts, of varying types, represented as inside a containing concept. This is easy to do in CmapTools. Typically the containing concept represents a sub-system of some kind. These correspond to the UML links terminated by diamond shapes (open and filled).
- Relationships typically called “kind of” or “is a” correspond to the UML sub-class relationship, given with an open triangle terminator. As these should always be between concepts of the same essential type, these can be picked out easily by being a uniform colour for the minimized and detailed representations of the whole.
So, all in all, a very stimulating meeting. Watch this space for further installments as trailed above.