How are projects tracking the use of their OER? What tools are projects using to work with their OER collections? This is a post in the UKOER 2 technical synthesis series.
[These posts should be regarded as drafts for comment until I remove this note]
Analytics
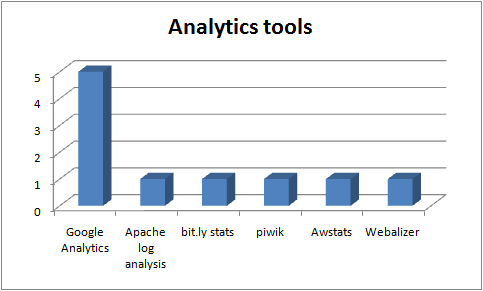
Analytics and tracking tools in use in the UKOER 2 programme
As part of their thinking around sustainability, it was suggested to projects that they consider how they would track and monitor the use of the open content they released.
Most projects have opted to rely on tracking functionality built into their chosen platform (were present). The tools listed in the graph above represent the content tracking or web traffic analysis tools being used in addition to any built in features of platforms.
Awstats, Webalizer and Piwik are all in (trial) use by the TIGER project.
Tools
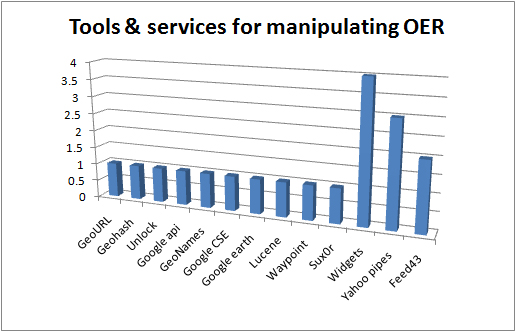
Tools used to work with OER and OER feeds in the UKOER 2 programme
These tools are being used by projects to work with collections of OER, typically by aggregating or processing rss feeds or other sources of metadata about OER. SOme of the tools are in use for indexing or mapping, others for filtering, and others to plug collections or search interfaces into a third-party platform. The tools are mostly in use in Strand C of the programme but widgets, yahoo pipes, and feed43 have a degree of wider use.
The listing in the above graph for widgets covers a number of technologies including some use of the W3C widget specification.
The Open Fieldwork project made extensive use of coordinate and mapping tools (more about this in a subsequent post)
Pingback: UKOER 2: Technical synthesis introduction